for-rag-competition-experience
一次RAG竞赛实战分享,详述从PDF解析、数据清洗、向量检索、LLM重排到系统化提示词设计的全流程经验与关键技巧。
发布时间:2025 年 3 月 25 日
一篇老文了,最近遇到一些RAG的问题,回看了一下,觉得还是有启发,因此翻译分享一下。
从零到 SOTA:在一场竞赛里把系统做到顶 这场 RAG Challenge 到底比什么? 这次比赛的任务是:基于公司年度报告 (Annual Reports)搭建一个问答系统。比赛当天流程大致如下:
主办方会随机挑选公司,给你 100 份年度报告 ,并给你 2.5 小时 把它们解析并构建成可检索的数据库。报告都是 PDF,每份可能长达 1000 页 。 然后系统会根据预定义模板生成 100 个随机问题 ,你的系统需要尽可能快地给出答案。 这些问题都必须是“有确定答案”的类型,例如:
更重要的是:每个答案必须附带证据页引用 (指出报告中对应的页码),从而证明答案确实来自文档而不是模型“编造”。
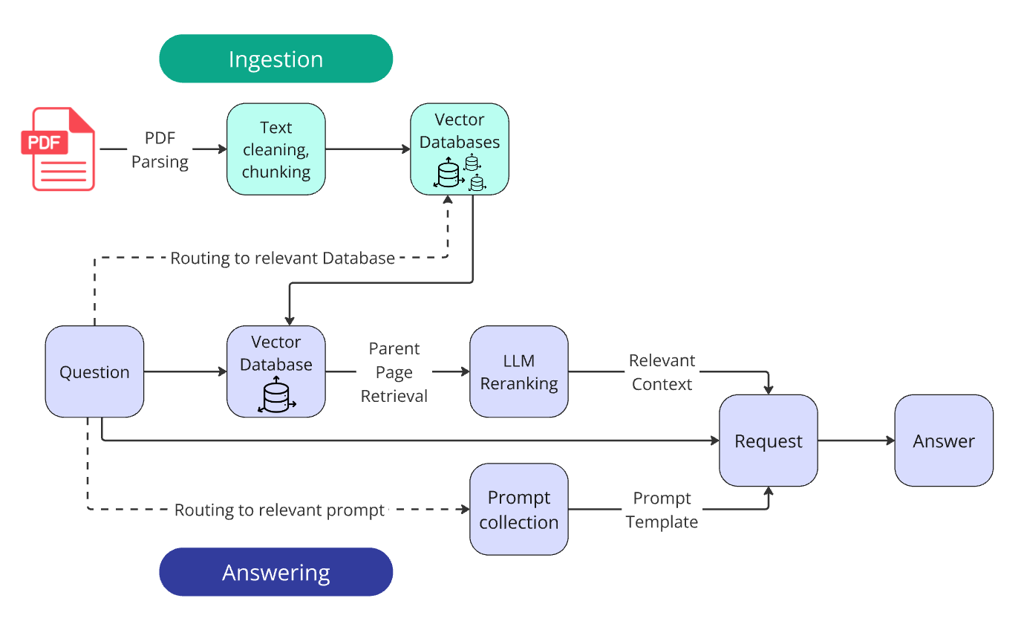
获胜系统的总体架构
除了一条“常规 RAG 流水线”之外,冠军方案还引入了
两层 Router(路由器) 与
LLM 进行重排(Reranking) 。
你可以在这里查看我表现最好的系统输出的问答结果:
answers_1st_place_o3-mini.json 接下来我会按步骤拆解整个系统:从构建过程中的坑与代价,到最终沉淀的最佳实践。
RAG 速览:一个基础系统通常分 4 段 RAG(Retrieval-Augmented Generation,检索增强生成)是一类方法:通过把大型语言模型(LLM)与任意规模的知识库结合,来扩展其回答能力。
一个最基础的 RAG 系统通常包含以下四个阶段:
Parsing(解析) :收集文档,把 PDF 等格式转成可处理的文本,并清理噪声Ingestion(导入) :把清洗后的内容写入知识库/索引Retrieval(检索) :根据问题从知识库中找回相关内容(通常用向量检索)Answering(回答) :把检索结果拼入提示词,让 LLM 生成最终答案1. Parsing:解析 PDF 的“地狱级”难度 要往数据库里灌任何内容,第一步都是把 PDF 转成纯文本。但现实是:PDF 解析并不简单,里面有无数细节坑,例如:
我遇到但没时间彻底解决的有趣问题 有些大表格会整体旋转 90 度 ,导致解析出来全是乱码、不可读
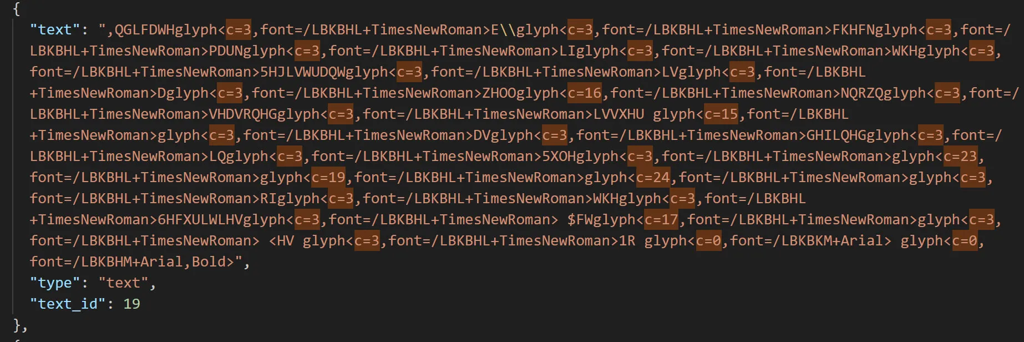
有些图表一部分是图片,一部分是文本层(解析器很容易混乱) 有的文档存在字体编码 问题:肉眼看正常,但复制/解析得到一串无意义字符
额外彩蛋:我单独研究过这种编码问题,发现它其实可解——更像是“凯撒加密”,而且每个单词的 ASCII 位移还不一样。于是我开始好奇:如果真有人故意把公开年报的可复制文本加密——为什么?如果是转换过程出了错——又为什么偏偏会变成这种形式?
选择解析器:没有“万能选手” 我大概试了 二十多个 PDF 解析器 ,包括:
结论很明确:到目前为止,没有任何一个解析器 能覆盖所有细节,并在不丢失关键信息的情况下把 PDF 完整还原为高质量文本。
这次比赛里表现最好的解析器,是相对知名的
Docling 。有意思的是,它背后正是比赛主办方之一
IBM 。
解析器改造:把缺的能力补齐 Docling 的效果很好,但仍缺少一些关键能力。更麻烦的是:这些能力虽然“局部存在”,却散落在不同配置里,无法合在一次运行里同时启用。
于是我直接读源码,重写了几个核心方法,让解析输出变成一个包含全部必要元数据的 JSON。然后我再用这个 JSON 去生成 Markdown,并且把表格结构做了纠正,最终能做到:表格不仅转成 MD,还能转成 HTML (这在后续很关键)。
Docling 本身速度很快,但要在个人笔记本上把 15000 页 在 2.5 小时 内解析完仍不够。解决方案是:用 GPU 加速解析,并在比赛时租了一台带 4090 的云主机——成本大概 0.7 美元/小时 。Runpod 在短租 GPU 上非常方便。
最终,解析 100 份文档耗时约 40 分钟 。根据其他选手的反馈,这已经是非常高的解析速度了。
到此为止,我们得到的是“解析后的 JSON”。
那能直接写入数据库了吗?还不行:接下来还得降噪 ,并对表格做预处理。
文本清洗与表格准备 有时 PDF 解析会输出一些特殊语法/碎片文本,严重影响可读性和语义。我用了一组大约十来条正则表达式,批量清理掉这些噪声。
坏解析文本示例:
对于前面提到的“凯撒加密式”文本,我也用 regex 模式识别出来,尝试过解码,但还原后仍然有大量伪影。最后我选择对这类文档直接全量走 OCR。
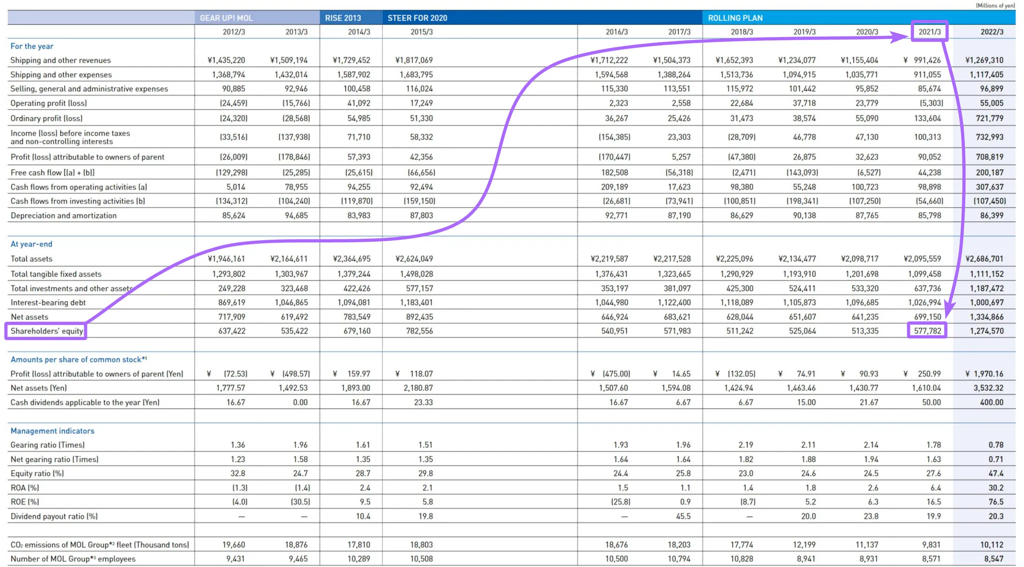
表格序列化(Table Serialization) 大型表格常见的问题是:横向表头(指标名)与纵向表头(维度/年份等)之间隔得很远,语义关联被稀释。
比如:纵向表头与横向表头之间可能隔着 1500 个无关 token :
这会显著降低向量检索时 chunk 的相关度(更别说表格经常被切成多块)。同时,大表格也让 LLM 更难正确把指标名与表头对应起来,容易读错数。
解决思路是:序列化 ——把大表格转成一组“上下文自洽”的小字符串。关于这块的公开研究并不多,我基本是自己摸索。你可以搜索:
序列化的本质:把表格变成很多独立文本块。经过大量 prompt 与结构化输出(Structured Output)实验,我找到一种方法:即使是 GPT-4o-mini 也能几乎无损地完成超大表格的序列化。
我最初把表格用 Markdown 交给模型,但后来改用 HTML (前面说的“表格转 HTML”就派上用场了):模型对 HTML 的理解更好,而且能更好表达合并单元格、子标题等复杂结构。
例如,要回答“公司 2021 年股东权益是多少?”这种问题,只需要喂给模型一句话,而不是塞一整页表格噪声。
序列化后会生成类似这样的块:
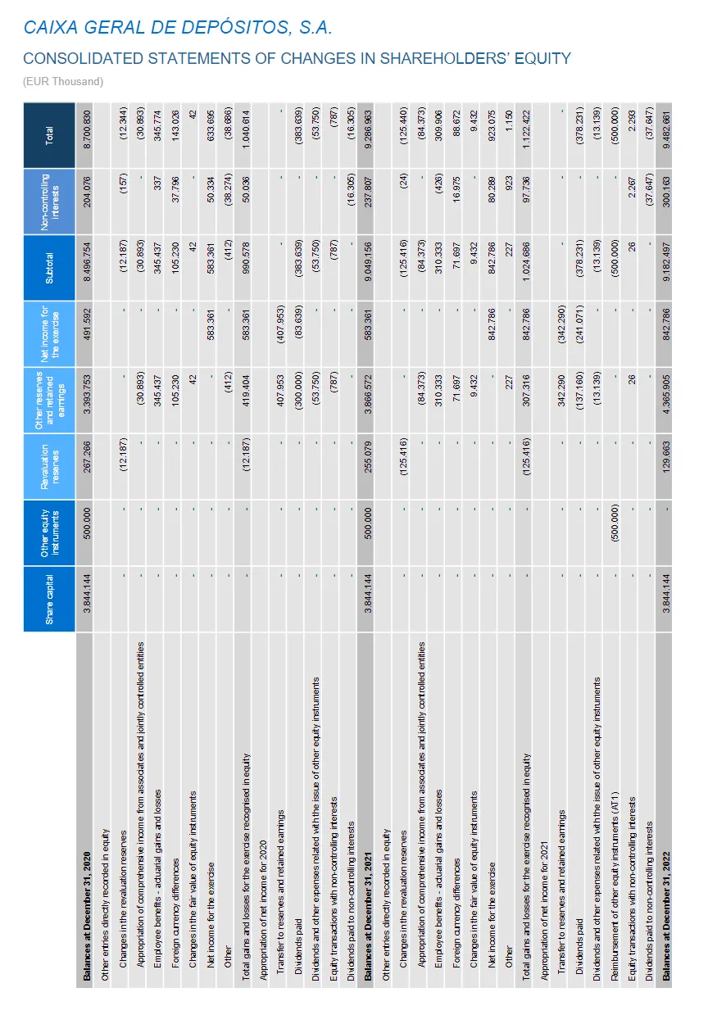
subject_core_entity: Shareholders' equityinformation_block: Shareholders' equity for the years from 2012/3 to 2022/3 are as follows: ¥637,422 million (2012/3), ¥535,422 million (2013/3), ¥679,160 million (2014/3), ¥782,556 million (2015/3), ¥540,951 million (2016/3), ¥571,983 million (2017/3), ¥511,242 million (2018/3), ¥525,064 million (2019/3), ¥513,335 million (2020/3), ¥577,782 million (2021/3), and ¥1,274,570 million (2022/3).拿到序列化文本后,我会把它放在原表格下面,作为一种“文本注释”。
*尽管序列化看起来潜力巨大,但最终冠军方案并没有在最终系统中使用它 。原因我会在文章末尾解释。
2. Ingestion:把文档写进数据库之前,先统一术语 到这里,报告已经从 PDF 转成干净的 Markdown 文本。下一步是创建数据库并把内容导入。
在搜索系统领域(Google Search、全文检索、Elastic、向量检索等),“document”指的是搜索系统返回的最小索引单元,可能是一句话、段落、页面、网站、图片……几乎什么都可以。
但这个定义和日常语义里的“文档(年报/合同/证书)”冲突很大,容易把自己绕晕。
所以在后续叙述里:
document :我都按日常语义使用(也就是一份报告/文档)Chunking:怎么切块更合理? 比赛规则要求我们输出证据页码,企业级系统也常用同样策略:引用能证明模型答案不是瞎编,同时也更便于开发阶段排查问题。
最简单的 chunk 策略是:一页一个 chunk 。因为单页一般不会超过几千 token(当然表格序列化可能会把单页扩到五千 token)。
但从“语义相关性”的角度考虑,一个问题对应的关键事实通常不需要那么大范围。通常十来句就够了。
因此同一句话:
最终我选择按页拆分后,再把每页切成 300 token 的 chunk(约 15 句),并加 50 token overlap 防止切断信息。
如果担心 overlap 不够,建议搜索“Semantic splitter”(尤其是你打算只把命中的 chunk 塞进上下文时)。
不过,在我的系统里,切块精细度对最终效果影响并不大。
每个 chunk 还会在元数据里记录:chunk ID 与其所属页码。
Vectorization:一份报告一个向量库 chunk 准备好后,下一步就是建向量数据库——更准确地说,是建很多个 向量数据库。
我把 100 份报告拆成 100 个独立索引 ,也就是:1 份报告 = 1 个向量库 。
原因很简单:为什么要把所有公司的信息混在一个大池子里,之后还得费力区分“苹果的营收”和“微软的营收”?一个问题的答案通常严格来自同一份报告 。
因此我们的关键任务变成:先判断该查哪份报告(后面会讲 routing)。
向量库索引格式的一点说明 我用 IndexFlatIP 来建索引。
Flat 索引的好处:向量“原样存储”,搜索是暴力匹配,精度更高 当你的向量数量达到十万级,建议考虑 IVFFlat 或 HNSW:检索更快,但属于 ANN(近似最近邻),速度提升以精度为代价。
由于我把每份报告拆成独立索引,规模被拆小,所以 Flat 索引可行。
相似度我用 IP(inner product)去近似 cosine similarity。除 IP 外也常见 L2(欧氏距离),但 IP 通常效果更好。
3. Retrieval:真正决定“能不能答对”的环节 向量库建完,就轮到 RAG 的 “R”(Retrieval)了。
Retriever 的定义很简单:输入一个 query,返回与之相关的文本(包含回答所需的信息)。
在最基础版本里,就是向量库检索 Top-N chunk。
但检索是整个系统的关键:如果 LLM 的上下文里没有关键证据,再好的 prompt 也无济于事。
Junk in → Junk out 。
比赛中我尝试过多种提升检索质量的方法,主要包括:
混合检索:向量检索 + BM25 Hybrid Search 的思路是:把语义检索(向量)与关键词检索(BM25)结合,理论上能兼顾“语义”与“精确词命中”。
典型做法是:两路检索各出一批结果,再做合并与重排。
但在我最小实现版本里,这个策略经常不升反降 。
总体来看,Hybrid Search 仍是一个很有价值的方向,尤其可以通过“改写 query”来提升关键词密度:比如让 LLM 先去掉噪声、重写问题再走 BM25。
如果你对 Hybrid Search 有很好的实践经验(尤其是踩坑与修复手段),欢迎留言交流。
Cross-encoder 重排:效果好但生态限制 Cross-encoder 能对 query 与文本对进行更精确的相关性判断,比只比较 embedding 向量更准确。
问题在于:如果对全库做 pairwise 比对,会太慢,所以它只适合在向量检索先筛出一小批候选后做重排。
我最后放弃这个方向,是因为当时可用的“API 版 cross-encoder”选择太少:OpenAI 或其他大厂并没有直接提供这种能力,我也不想再维护一套额外的推理服务和余额管理。
如果你想试试,我推荐
Jina Reranker :benchmark 表现不错,注册后也有较多免费额度。
最终我选择了一个更“顺手”的替代:LLM 重排 。
LLM 重排:便宜、快、够好 思路非常直接:把文本块与问题一起发给 LLM,问它:
这段文本对回答这个问题有帮助吗?有多大帮助?请给出 0 到 1 的相关性分数。
以前这样做太贵,但现在我们有足够便宜、够快且足够聪明的模型。
LLM 重排和 cross-encoder 类似:都放在向量检索筛选之后做。
我写了一个相对详细的评分提示词,明确 0.1 为粒度的标准:
模型输出我用 Structured Output(结构化输出),包含两个字段:
为了提速、降本、也让评分更稳定,我把 三页一起发 给模型,请它一次返回三条分数。
最终“纠正后的相关性”用加权平均融合:
理论上你也可以完全不做向量检索,把所有页面都喂给 LLM 评分。但这在成本上不划算:对一份 1000 页报告,回答一个问题大约要 0.25 美元 ——太贵。
向量检索作为第一层过滤仍然必要。我的方案里,使用 GPT-4o-mini 做 LLM 重排,每个问题的重排成本 不到 1 美分 ,性价比非常高。
“父页回收”(Parent Page Retrieval):chunk 只是指针 还记得我把文本切成小 chunk 吗?这里有个关键点:
虽然答案信息通常集中在一个小 chunk 里,但同一页的其它文本往往包含“次要但仍重要”的上下文。
因此我在检索到 Top-N chunk 后,并不直接把 chunk 塞进提示词,而是把 chunk 当作“指针”,再把它对应的整页 作为上下文送入后续流程。
这也是为什么 chunk 的元数据里必须带页码。
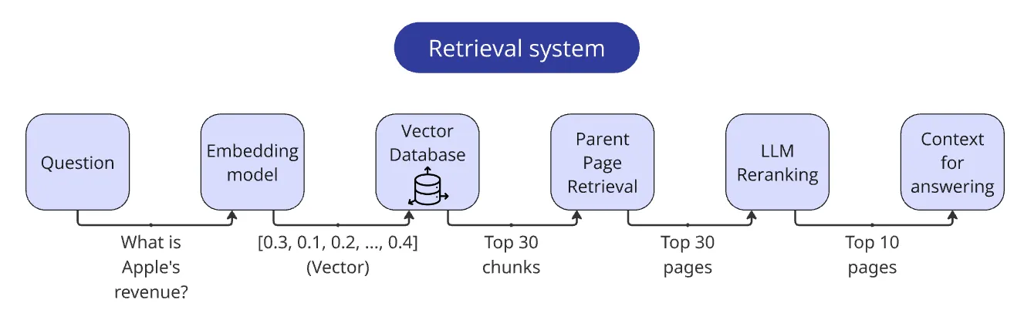
最终的 Retriever 流水线(总结)
完整检索流程如下:
把 query 向量化 在向量库里取 Top 30 chunk 通过 chunk 元数据取回对应页码,并去重 把这些页丢给 LLM 做重排 用向量分数与 LLM 分数组合修正 取 Top 10 页,把每页加上页码前缀并拼成一个字符串作为上下文 Retriever 就绪。
4. Augmentation:拼上下文其实就是字符串工程
向量库与 retriever 搭好后,就进入 “A”(Augmentation)阶段。它整体很直白:主要就是字符串拼接(f-strings)与上下文组织。
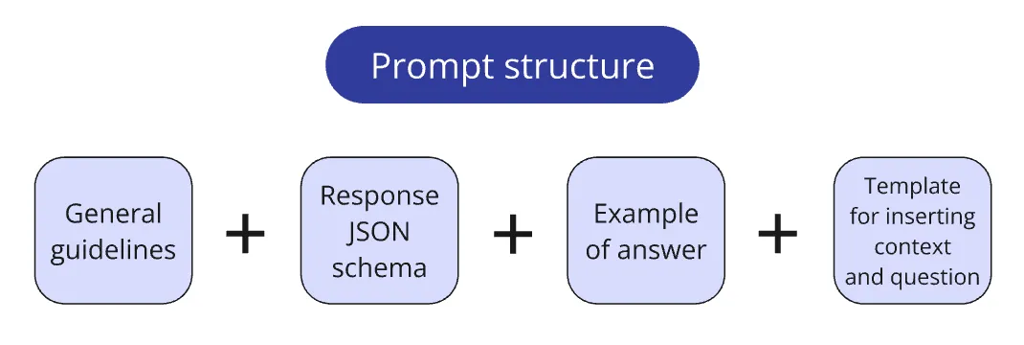
一个值得分享的细节是:我如何管理提示词(prompt)。
在做过多个项目的尝试后,我最终固定采用这样的组织方式:
prompt 按逻辑块拆分存储,例如: 核心 system instruction Structured Output schema(期望的输出结构) one-shot / few-shot 的示例问答 拼接上下文与 query 的模板 然后用一个小函数把这些块组合成最终 prompt 配置。
这个模式的收益是:
对“多处复用的通用指令”只维护一份,避免同步更新出错 完整 prompts 在仓库:
prompts.py 5. Generation:最费工、但也最能拉开差距 RAG 的 “G”(Generation)通常是最劳累的部分:要达到高质量,得同时把多种基本功做好。
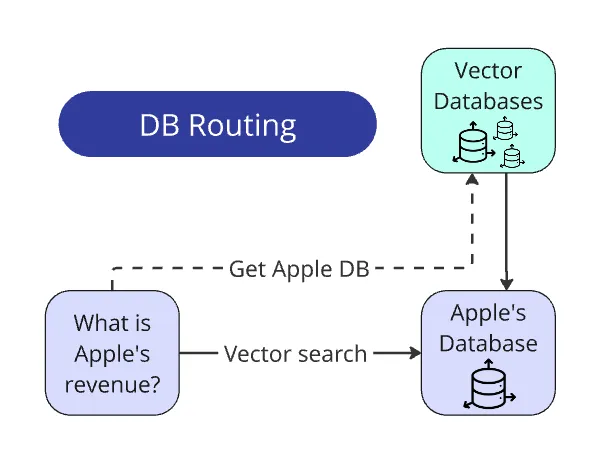
把问题路由到正确的数据库(Routing: Query → DB)
这是最简单但极其有用的一步。
比赛的题目生成器设计得很“干净”:公司的名字一定会在题干里明确出现。
同时,比赛开始时会提供一份全部公司名称列表。因此,识别公司名完全不需要 LLM:只要遍历名单,用 re.search() 从问题里抽取公司名,再映射到对应向量库即可。
真实业务场景里会更复杂:你可能还需要先给文档打标签,或用 LLM 从问题里抽实体,再对齐到某个库/某个集合。但本质不变:
找公司名 → 匹配 DB → 只在该 DB 内检索 ,搜索空间直接缩小 100 倍。
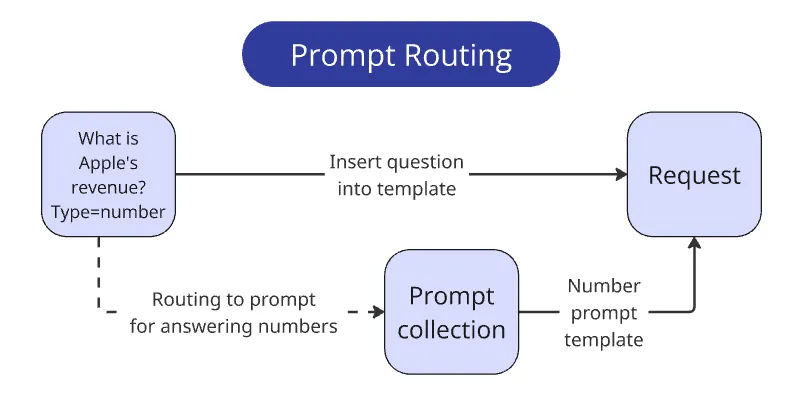
把问题路由到正确的 prompt(Routing: Query → Prompt)
比赛还有一个硬要求:答案格式必须严格符合预期类型,好像要直接写进数据库一样简洁。
题目里会明确标注答案类型:int/float、bool、str、list[str]。
每种类型都有 3~6 个容易犯错的细节。例如,数值类答案必须:
问题是:你不可能让模型一次性稳定遵守太多规则。规则越多,越容易被忽略。对当前 LLM 来说,八条规则 已经很危险——额外规则会分散注意力。
因此我采用的策略是:把规则分流 。既然题目明确给了答案类型,那么我就写四套 prompt,通过 if else 选用对应版本,只把与当前类型相关的指令塞进去。
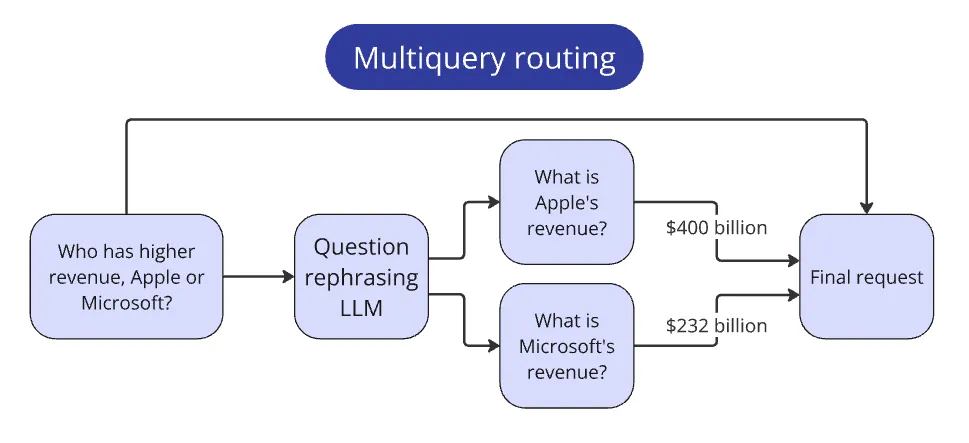
复合问题路由(Routing: Compound Query)
比赛里还有一种题:比较多个公司指标,例如:
Who has higher revenue, Apple or Microsoft?
这种题不适合直接走“单次检索-单次回答”。人类会怎么做?
1) 先分别找出 Apple 的营收
2) 再分别找出 Microsoft 的营收
3) 然后比较
我把这个过程显式写进系统:先让 LLM 把比较题拆成两个子问题(分别抽指标),再把两个子问题分别走标准 pipeline,最后把两边答案作为上下文,再回答原始比较题。
这个模式可以推广到各种复杂查询:关键在于识别其结构,并拆成必要子步骤。
Chain-of-Thought(CoT):让模型“按步骤推理” CoT 的核心价值是:让模型在给最终答案前先“把推理过程说出来”。像人一样把复杂问题拆成更小步骤,能显著提高正确率,尤其是当上下文里有很多“相似但不等价”的信息时。
你可能听过早期最经典的提示词:Think step by step。它确实开启了 prompt engineering 的浪潮,但对于严肃任务远远不够。
LLM 也会“假装推理”:先拍一个答案,然后倒过来编一段推理去解释它。弱模型(例如 GPT-4o-mini、Llama 8b)尤其常见。
因此要让 CoT 真正有用,你需要明确告诉模型应该如何推理:步骤目标是什么、需要检查什么、最好还要给例子。把推理结构显式化,也能显著提升模型对规则的遵循。
在 RAG 场景里,一个常见问题是:报告里没有“完全匹配”的指标,但有相近指标。模型因为“想帮你”,容易把相近信息硬掰成答案。仅靠一句“保持怀疑”并不稳定。
我最终的策略是:明确要求模型在推理里重点评估“题目指标与上下文指标是否同一个口径”,不匹配则必须返回 N/A。
一个上下文含糊的推理示例 问题:
What is the Research and development equipment, at cost, for Ritter Pharmaceuticals, Inc.?
模型推理步骤(重写表达,但信息保持一致):
问题要的是 Ritter Pharmaceuticals, Inc. 的“研发设备(按成本计)”。这里的“at cost”意味着要的是设备原始购置成本,而不是折旧后净值。 上下文(第 35 页)给的是 Property and equipment, net 为 $12,500。这个是净值(扣除折旧后),而且范围也更广,不等同于“研发设备成本”。 上下文(第 37 页)提到 Accumulated Depreciation 为 $110,000,针对 Machinery and Equipment。这只是累计折旧,不是成本,而且也没有说明是研发设备。 这两项都无法与问题指标严格对齐:一个口径太宽且是净值,一个只给折旧且缺乏“研发设备”的限定。 因此上下文并未直接给出所需指标,不能推算或假设,最终答案应为 N/A。 Structured Output(结构化输出):把输出锁进 JSON Structured Output(SO)本质上是用一个严格的结构(例如 Pydantic/JSON schema)约束模型输出,确保返回值始终可解析、字段完整。
例如做 LLM 重排时,我用一个包含两个字段的 schema:reasoning 与 relevance_score。
如果一个模型原生支持 SO,就可以直接做到“永远返回合法 JSON”。字段描述也可以写入 schema,作为 prompt 的一部分,进一步引导模型。
CoT + SO:推理与答案分开存 理想情况下,这些方法要组合起来用。
在 generation 阶段,模型输出里会有一个字段专门放推理,另一个字段专门放最终答案。这样我们只取最终答案字段即可,避免从长推理里再做字符串解析。
我主力回答 schema 里有四个字段:
step_by_step_analysis:完整推理(CoT)reasoning_summary:对推理做简明摘要(便于追踪)final_answer:最终答案(严格按题目类型格式化)前三个字段在不同答案类型下通用;第四个字段会随答案类型变化,并在 schema 中做硬约束。
例如要确保 final_answer 要么是数字要么是 "N/A",我会用类似定义:
final_answer: Union[float, int, Literal['N/A']]
SO Reparser:让“不听话的模型”回炉重写 并非所有模型都支持“原生 Structured Output”。如果模型只是在 prompt 里看到 schema,它通常能返回合法 JSON,但仍会有一部分输出偏离结构,导致程序崩溃——小模型可能一半都不合规。
我的兜底做法是:
先用 schema.model_validate(answer) 校验输出 如果校验失败,就把模型的输出再发回给模型,让它“按 schema 重新输出一遍” 这能把 schema compliance 拉回到 100%,即使是 8b 模型也一样。
One-shot:用一个高质量示例“定调” 另一个常见且有效的方法是 one-shot:在 prompt 里加一个“问题→答案”的示例对,能显著提升输出一致性。
我在每套 prompt 里都加了一个示例,示例答案直接按 Structured Output 的 JSON 结构写。
示例的作用不止一个:
我对示例答案的质量要求非常严格:示例若与指令矛盾,会直接把模型搞糊涂,导致效果下降。
指令打磨:最耗工的部分 这一部分的工作量几乎不亚于“数据准备阶段”。因为你需要不断:
先把“问题本身”研究透 写 prompt 之前,我把题目格式要求与题目生成器都仔细研究了一遍,并生成题目做了一套验证集,手动去回答一部分题,主要为了两件事:
验证集能客观衡量系统质量变化(改动后到底提升了多少) 人工答题能暴露很多题目隐藏细节与歧义,从而把规则写清楚 我非常认同一个观点:要做高质量 QA 系统,必须先深度理解用户/客户的问题是什么——否则很难做到稳定可靠。
“解释自由阈值”问题(Interpretation Freedom Threshold) 举个例子:问题问 Who is the CEO of ACME inc?
理想情况下,报告会明确写:
CEO responsibilities are held by John Doe
这时系统很简单:检索到这句话,答案就是 John Doe。
但现实是:信息表达方式千差万别,“CEO”究竟指谁?可能出现的职位包括:
Chief Executive Officer(最直接) Managing Director(欧洲/英国常见) Executive Director(非营利/一些地区) 甚至还有 COO、Principal Executive Officer、General Manager、Administrative Officer、Representative Director 等“相近但不等价”的角色 当答案允许自由表达时,模型可以把这些不确定性写成解释。但在比赛这种“必须短、必须严格类型”的场景里,模型会变得很不稳定,更多靠“直觉猜”。
因此需要提前定义并校准“解释自由阈值”:哪些情况允许放宽解释,哪些情况必须严格字面匹配——但这又很难用一条明确规则穷举,所以你需要系统性枚举边界情况,反复调参。
除此之外还有其它两难题,例如:
Did ACME inc announce any changes to its dividend policy?
如果报告里没有提到分红政策变化,是否应当返回“没有变化”?还是“未知”?
这类问题在准备阶段我问了组织者很多次 :)
Prompt 版本与配套 prompt 清单 我最终为每种问题/输出类型做了不同 prompt,并额外准备了辅助 prompt:
比较题(Comparative:需要多查询路由与比较) 比较题的改写 prompt(用来把复合问题拆成子问题) 指令的精细打磨 + one-shot + SO + CoT 的组合,让最终 prompt 能稳定压制一些不想要的偏置,并显著提升对细节(尤其是单位、口径)的关注度,即使在小模型上也有明显收益。
系统速度:2 分钟跑完 100 题 最初的比赛规则更严格:必须在 10 分钟内 回答完 100 题才有资格领奖。我非常认真对待这个限制,并尝试把 OpenAI 的 TPM(Tokens Per Minute)上限用满。
即使是 Tier 2,限制也很宽松:GPT-4o-mini 为 2M tokens/min ,GPT-4o 为 450k tokens/min 。我估算了每题 token 消耗后,把问题分成每批 25 个并行处理。
最终系统只用了 2 分钟 就答完 100 题。
后来提交时限被大幅延长——因为其他选手确实跑不完 :)
系统质量:表格序列化反而没带来提升 验证集不仅帮助我优化 prompt,也帮助我评估整条 pipeline 的关键开关。我把关键策略都做成配置项,便于 A/B 测试。示例配置如下:
class RunConfig:
use_serialized_tables: bool = False
parent_document_retrieval: bool = False
use_vector_dbs: bool = True
use_bm25_db: bool = False
llm_reranking: bool = False
llm_reranking_sample_size: int = 30
top_n_retrieval: int = 10
api_provider: str = "openai"
answering_model: str = "gpt-4o-mini-2024-07-18"
在多轮测试里我意外发现:我很看好的“表格序列化”不仅没有提升,反而略微降低了效果。
原因可能是:Docling 对 PDF 表格解析已经足够好,retriever 也能有效命中,LLM 也能在不序列化的情况下理解表格结构;而序列化会让页面文字变多、噪声变大,反而降低信噪比。
我还为比赛准备了多套配置,方便在不同类别下快速切换不同系统版本。
最终系统在开源与闭源模型上都表现不错:Llama 3.3 70b 只比 OpenAI o3-mini 低几个点;甚至 Llama 8b 也能超过 80% 的参赛者。
结语:RAG 的“魔法”来自细节 赢得这场比赛并不是因为某个“神奇单点”,而是因为系统化地把每个环节都做到位,并在细节上反复打磨:高质量解析、有效检索、智能路由,以及最关键的——LLM 重排与精心设计的提示词,让系统即使在更小的模型上也能获得优秀表现。
这次经历最大的收获是:RAG 的魔法藏在细节里 。你越理解任务,就越能精准调优每一个模块;即使使用最朴素的方法,也能获得更高收益。
系统代码已开源,包含部署与运行各阶段的说明:
abdullinIlya Rice: How I Won the Enterprise RAG Challenge