Created time
Apr 13, 2026 04:28 PM
category
library
date
Apr 10, 2026
status
Published
icon
password
slug
for-multi-agent-coordination-patterns
type
post
likes
views
summary
如何选择合适的多智能体协作模式,以实现高效的任务处理和信息流动?
tags
工程实践
Claude
Agent
原文链接:https://claude.com/blog/multi-agent-coordination-patterns 发表日期:2026年4月10日
在之前的文章中,我们探讨了多智能体系统的价值所在,以及何时选择单一智能体更为合适。本文面向那些已经做出决定、但还在思考"用哪种协作模式"的团队。
我们发现,很多团队在选择模式时,往往偏爱听起来"高大上"的方案,而不是真正契合问题的那个。我们的建议是:从最简单可行的模式出发,观察它在哪里遇到瓶颈,再顺势演进。
本文将深入剖析五种模式的运作机制与局限性:
- 生成器-验证器(Generator-verifier):适用于对质量要求极高、且有明确评估标准的输出场景。
- 编排者-子智能体(Orchestrator-subagent):适用于任务分解清晰、子任务边界明确的场景。
- 智能体团队(Agent teams):适用于可并行、独立运行、需要长时间持续工作的子任务。
- 消息总线(Message bus):适用于事件驱动的流水线,以及智能体生态持续扩张的场景。
- 共享状态(Shared-state):适用于协作式工作,即各智能体需要在彼此研究成果的基础上继续深入。
模式一:生成器-验证器
这是最简单、也是应用最广泛的多智能体模式之一。我们在之前的文章中将其称为"验证子智能体模式",此处改用更通用的"生成器-验证器"框架——因为生成器不一定非得是编排者。
运作原理
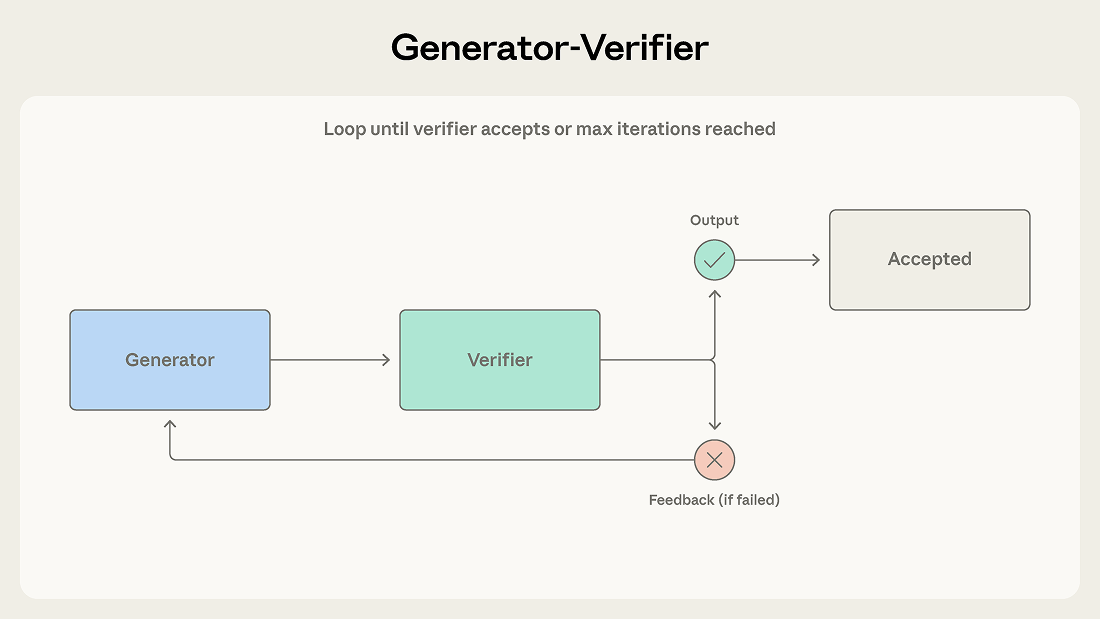
生成器接收任务并产出初稿,随后将其交给验证器进行评估。验证器根据既定标准决定是"通过"还是"打回"。若打回,反馈会返还给生成器,由其修改后再提交。如此循环,直到验证器通过,或达到最大迭代次数为止。
适用场景
以客服工单的邮件回复系统为例:生成器结合产品文档和工单背景生成初稿;验证器则对照知识库核查准确性、依据品牌规范评估语气,并确认是否回答了用户的所有问题。一旦不达标,反馈会明确指出问题——比如将某功能错误归入了错误的定价层级,或遗漏了工单中的某个问题。
当输出质量至关重要、且评估标准明确时,优先选择此模式。 它在以下领域效果尤佳:代码生成(一个智能体写代码,另一个写测试并运行)、事实核查、基于评分标准的内容打分、合规性验证。只要"输出错误的代价"远高于"多跑一轮生成的成本",该模式都值得采用。
局限性
验证器的效果,完全取决于标准的质量。如果只是笼统地要求"检查输出是否良好",而没有具体的判断依据,验证器只会照单全收。团队最常踩的坑,就是在没有定义"验证"含义的情况下就上了循环机制——营造出质量控制的假象,却毫无实质内容。
此外,该模式还假设"生成"和"验证"是可分离的能力。如果评估一个方案的难度与生成方案本身相当,验证器未必能可靠地发现问题。
最后,迭代循环可能陷入僵局:生成器无法解决验证器的反馈,系统就会反复震荡,无法收敛。务必设置最大迭代次数,并配备兜底策略——比如转交人工处理,或附带警告地返回当前最优结果——以防止无限循环。
模式二:编排者-子智能体
该模式的核心是层级结构:一个智能体充当"团队负责人",负责规划任务、委派工作并汇总结果;子智能体各司其职,向上汇报。
运作原理
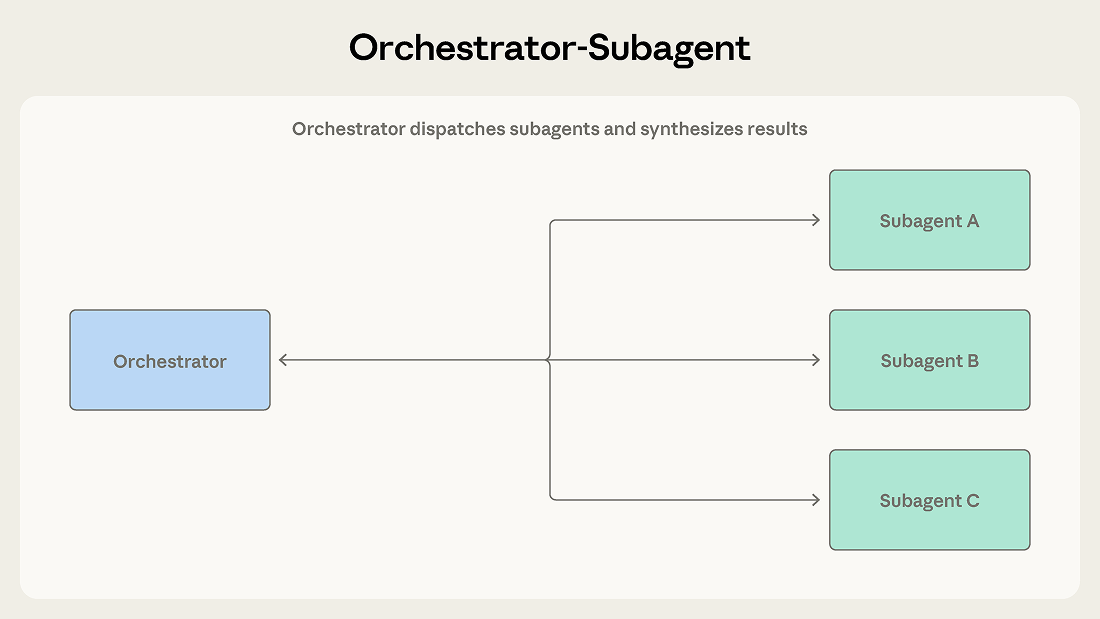
编排者接收任务后确定处理方式:部分子任务由自己直接完成,其余则分派给子智能体。子智能体完成工作后返回结果,编排者将其汇总为最终输出。
Claude Code 正是采用了这一模式。主智能体负责写代码、编辑文件和运行命令;在需要搜索大型代码库或排查独立问题时,它会在后台派出子智能体,在等待结果的同时保持主线进度。每个子智能体在独立的上下文窗口中运行,返回提炼后的结论,使编排者的上下文始终聚焦于主任务,同时实现并行探索。
适用场景
以自动化代码审查系统为例:收到 Pull Request 后,系统需要检查安全漏洞、验证测试覆盖率、评估代码风格、评价架构一致性。每项检查相互独立、需要不同的上下文,且输出明确。编排者将各项检查分派给专门的子智能体,收集结果后合成一份统一的审查报告。
当任务分解清晰、子任务间依赖性极小时,选择此模式。 编排者保持对整体目标的全局视角,子智能体专注于各自职责。
局限性
编排者会成为信息瓶颈。 子智能体之间的信息流转必须经由编排者中转。若安全子智能体发现了一个影响架构分析的认证漏洞,编排者必须识别这一依赖关系并合理路由。经过几轮交接后,关键细节往往会丢失或被过度概括。
顺序执行也会制约吞吐量:若未显式并行化,子智能体将依次运行——产生了多智能体的 Token 开销,却没有享受到速度提升。
模式三:智能体团队
当工作可以拆解为可长时间独立运行的并行子任务时,"编排者-子智能体"模式可能过于束缚。
运作原理
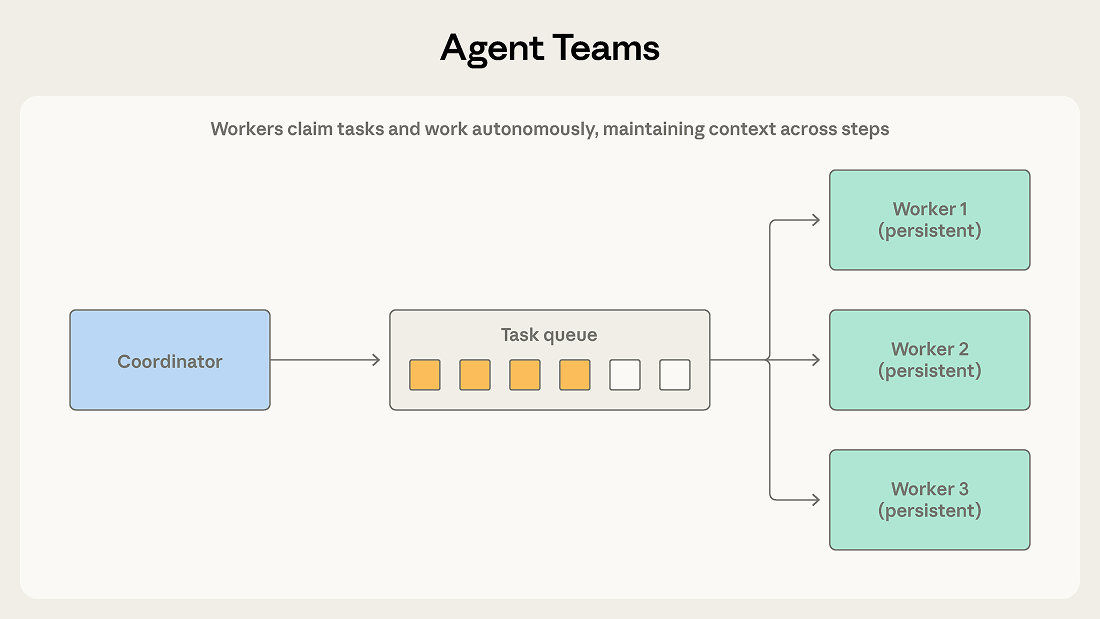
协调者将多个工作智能体作为独立进程启动。团队成员从共享队列中领取任务,自主完成多步骤工作,完成后发出信号。
与"编排者-子智能体"的关键区别在于工作者的持久性:编排者为单个有界子任务启动子智能体,任务完成即终止;而团队成员跨多次任务分配持续活跃,不断积累上下文和领域专知,随时间推移性能持续提升。协调者负责分发工作和收集成果,但不会在任务之间重置工作者的状态。
适用场景
以将大型代码库从一个框架迁移到另一个框架为例:团队成员可以独立迁移每个服务,各自处理依赖项、测试套件和部署配置。协调者将每个服务分配给一名成员,成员自主完成全流程:更新依赖、修改代码、修复测试、进行验证。协调者收集完成的迁移结果,最后运行全系统集成测试。
当子任务独立、且能从持续的多步骤工作中显著获益时,选择此模式。 每个团队成员会积累对所负责领域的深度上下文,而不是每次分派都从零开始。
局限性
独立性是硬性前提。 与编排者可以居中协调、路由信息不同,团队成员自主运行,无法轻易共享中间发现。若一个成员的工作影响了另一个,双方都无从知晓,可能产生冲突的输出。
完成检测也更复杂:成员以不同节奏运作,协调者必须妥善处理部分完成的情况。共享资源(如同一代码库、数据库或文件系统)则会进一步放大上述问题,需要仔细划分任务边界并设计冲突解决机制。
模式四:消息总线
随着智能体数量增多、交互模式趋于复杂,直接协调会变得难以维系。消息总线引入一个共享通信层,智能体通过该层发布和订阅事件。
运作原理
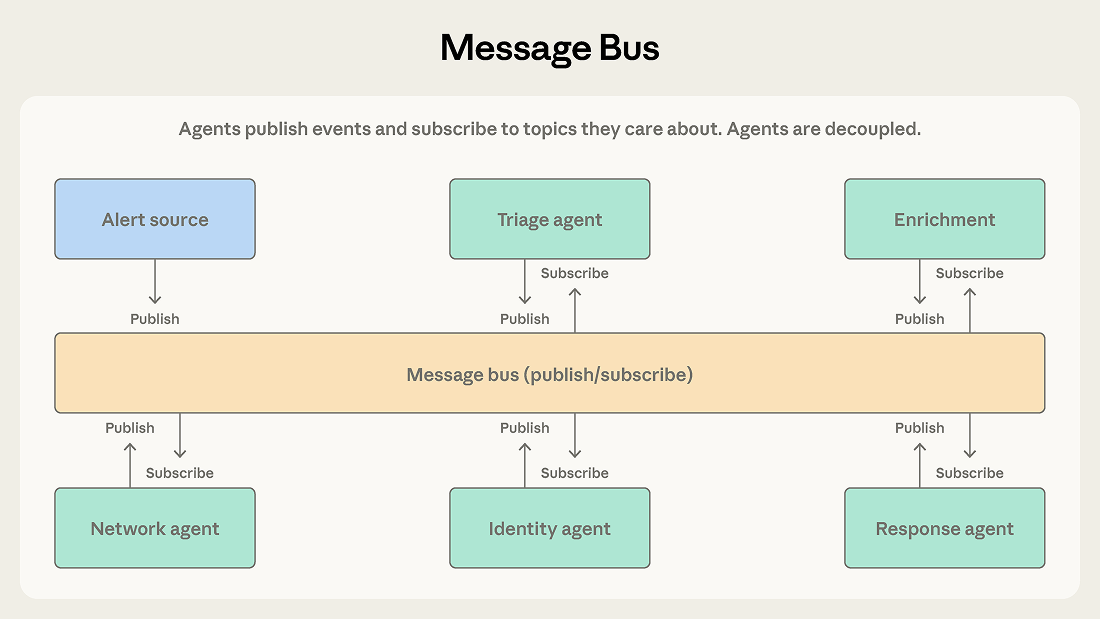
智能体通过两个原语交互:发布(Publish) 和 订阅(Subscribe)。路由器负责将消息投递给订阅了匹配主题的智能体。新加入的智能体无需重新配置现有连接,直接订阅相关主题即可开始接收工作。
适用场景
安全运营自动化系统是该模式的典型应用:警报从多个来源涌入,分诊智能体按严重程度和类型分类,将高危网络警报路由给网络调查智能体,将凭证相关警报路由给身份分析智能体。每个调查智能体可能发布信息丰富请求,由上下文收集智能体满足;结论流向响应协调智能体,由其决定下一步行动。
该流水线适合消息总线,因为:事件从一个阶段自然流向下一阶段;团队可以随着威胁类型的演变随时添加新的智能体;各智能体可以独立开发和部署。
当工作流由事件触发而非预定顺序驱动、且智能体生态可能持续增长时,选择此模式。
局限性
事件驱动通信的灵活性,同时也带来了可观测性难题。当一条警报触发了跨越五个智能体的连锁事件时,还原完整链路需要细致的日志记录和关联分析,调试难度远超顺序执行的编排者模式。
路由准确性同样至关重要:路由器一旦错误分类或丢弃事件,系统会静默失败——既不处理,也不报错。基于 LLM 的路由器提供了语义灵活性,但也引入了其特有的失败模式。
模式五:共享状态
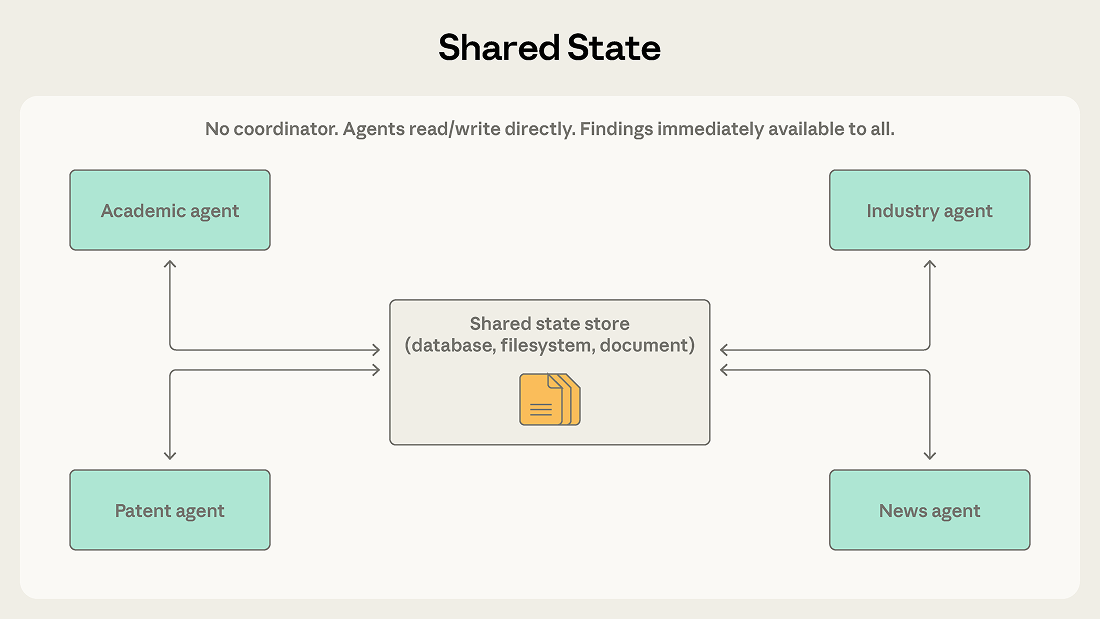
前面几种模式中,编排者、团队负责人和消息路由器都在集中管理信息流。共享状态则彻底去掉了中间环节——智能体通过一个所有人都能直接读写的持久化存储进行协作。
运作原理
智能体自主运行,从共享数据库、文件系统或文档中读取和写入内容,没有中央协调者。智能体扫描存储以获取相关信息,据此采取行动,再将结论写回。工作通常始于一个初始化步骤(向存储中注入问题或数据集),终于一个终止条件(时间限制、收敛阈值,或由指定智能体判定存储中已有足够的答案)。
适用场景
以多智能体研究综合系统为例:多个智能体各自调查复杂问题的不同维度——一个搜索学术文献,一个分析行业报告,一个查阅专利申请,一个监控新闻动态。各智能体的发现可能互相启发:学术文献智能体发现了某位关键研究人员,行业智能体就应该重点审查其所在公司。
有了共享状态,发现可以直接写入存储,行业智能体无需等待协调者转发即可立即看到。智能体在彼此工作的基础上持续深入,共享存储成为一个不断演进的知识库。
共享状态还消除了协调者这一单点故障:某个智能体停止工作,其他智能体仍可继续;而在编排者或消息总线架构中,核心组件的故障会让整个系统停摆。
局限性
缺乏显式协调,智能体可能重复劳动或采取相互矛盾的策略;两个智能体可能独立调查同一线索;系统行为由智能体交互涌现,而非自上而下设计,可预测性因此降低。
更严重的失败模式是"反应式循环":智能体 A 写下一个发现,智能体 B 读取后写下后续,智能体 A 看到后续再次响应……系统不断消耗 Token,却无法收敛。重复工作和并发写入有成熟的工程解决方案(锁定、版本控制、分区),但反应式循环是行为层面的问题,必须将终止条件作为一等公民认真设计:时间预算、收敛阈值(N 个周期内无新发现),或指定一个专门负责判断"答案是否足够"的智能体。把终止逻辑当作事后补丁的系统,要么无限循环,要么在某个智能体的上下文耗尽时随机中止。
如何选择模式,以及如何在模式间演进
正确的模式取决于对系统结构的几个关键判断。在之前的文章中,我们主张"以上下文为中心的分解"——根据每个智能体所需的上下文来划分工作,而非按工作类型划分。这一原则同样适用于此:不同模式之间的本质区别,在于它们管理上下文边界和信息流的方式。
编排者-子智能体 vs. 智能体团队
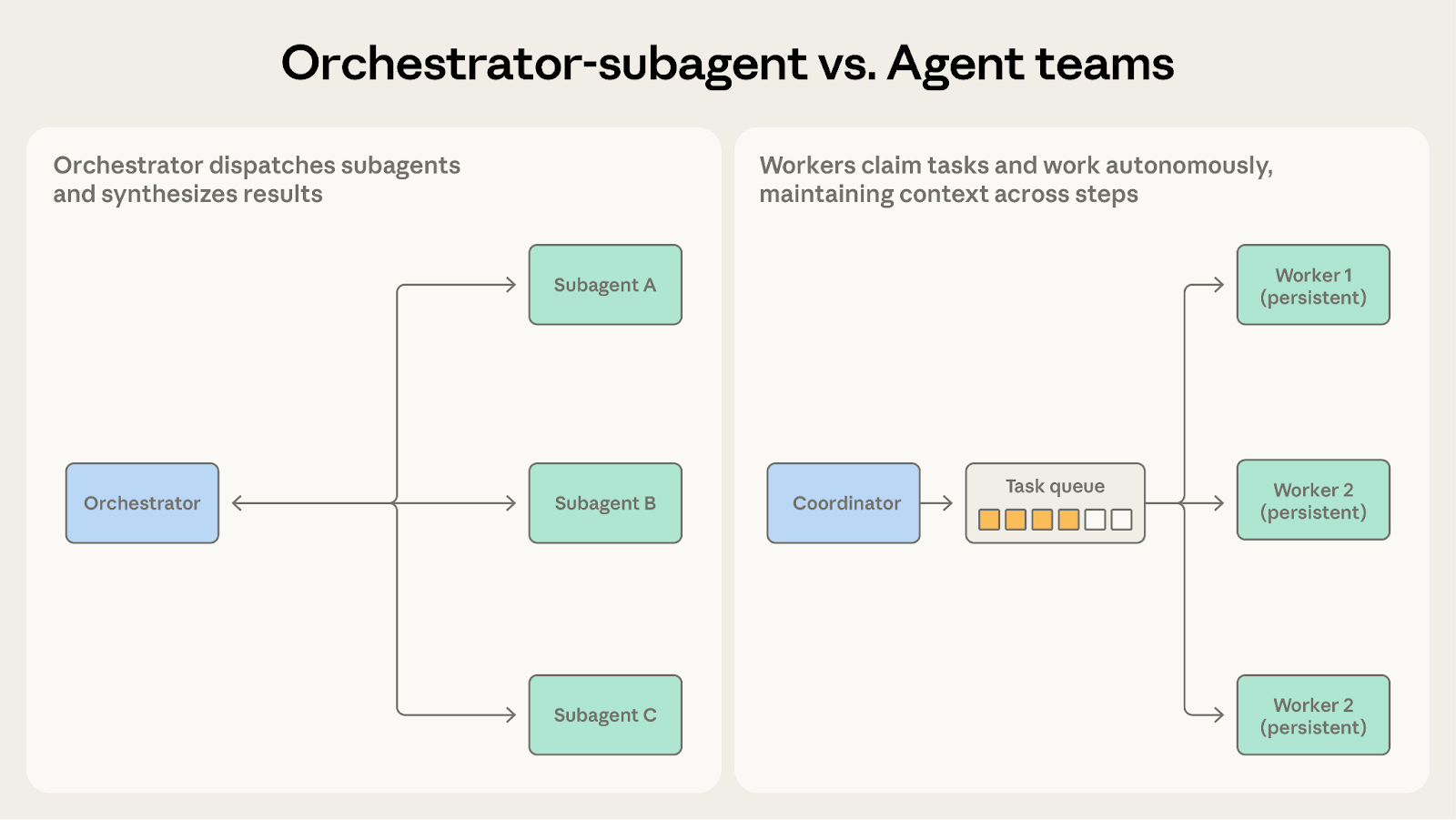
两者都涉及协调者将工作分派给其他智能体。核心问题是:工作者需要保持上下文多久?
- 选择编排者-子智能体:当子任务短小、聚焦、产出明确时。代码审查系统正是如此——每项检查在单次有界调用内完成分析、生成报告,子智能体无需跨周期携带上下文。
- 选择智能体团队:当子任务受益于持续的、多步骤工作时。代码库迁移更适合这一模式——每个成员对负责的服务形成了真正的熟悉感:依赖图、测试模式、部署配置。这种积累起来的上下文所带来的性能提升,是一次性分派无法复制的。
当子智能体需要跨调用保持状态时,智能体团队是更好的选择。
编排者-子智能体 vs. 消息总线
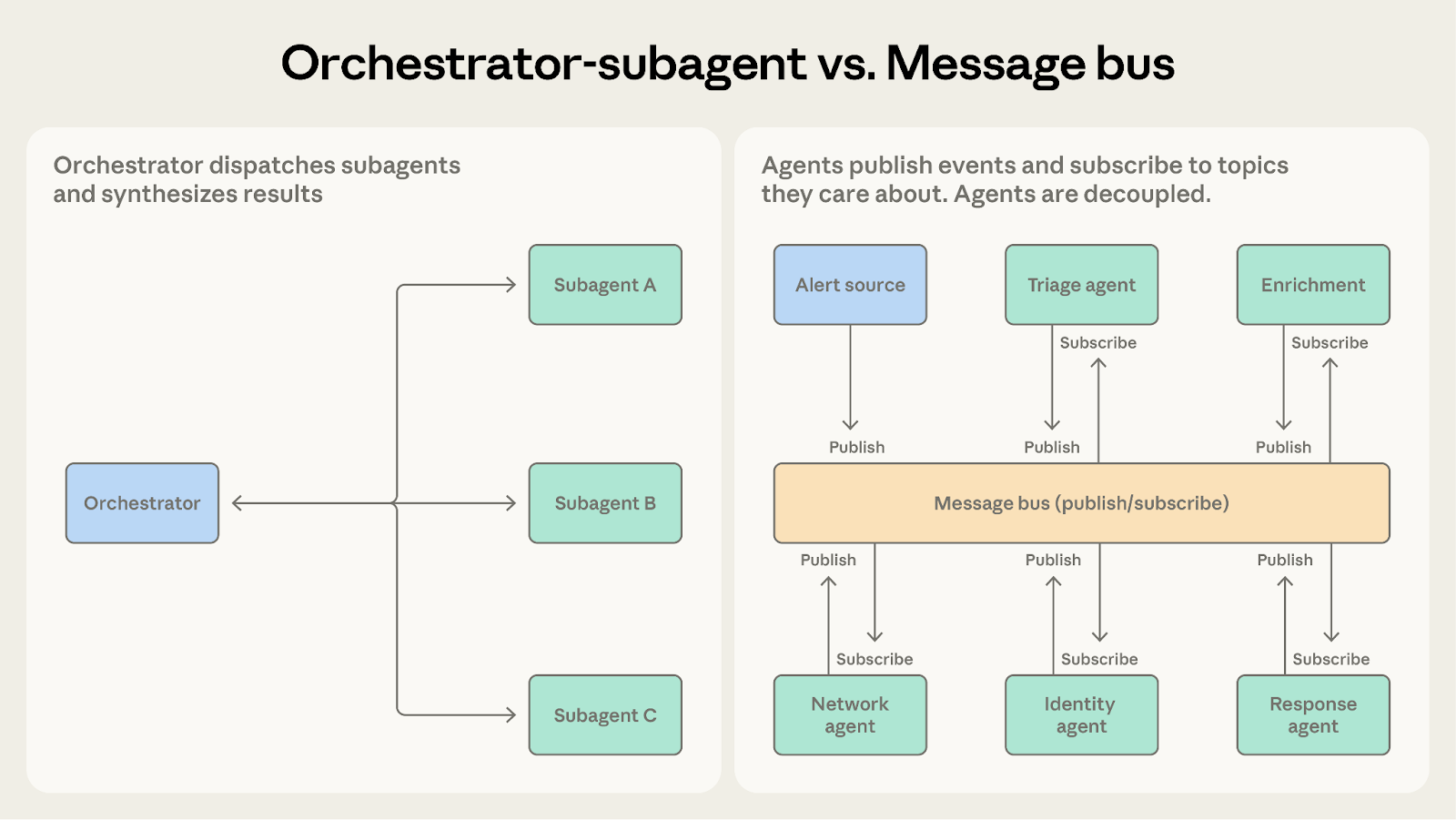
两者都能处理多步骤工作流。核心问题是:工作流的结构是否可以预知?
- 选择编排者-子智能体:当步骤顺序预先确定时。代码审查系统遵循固定流水线:收到 PR → 运行检查 → 合成结果。
- 选择消息总线:当工作流由事件动态产生、路径可能随发现而变化时。安全运营系统无法预测会收到什么警报、需要走什么调查路径,还可能出现需要全新处理方式的新型警报。消息总线通过将事件路由给有能力的智能体来适应这种可变性,而非遵循预定顺序。
当编排者中的条件分支逻辑越来越多时,消息总线能让这种路由变得显式且可扩展。
智能体团队 vs. 共享状态
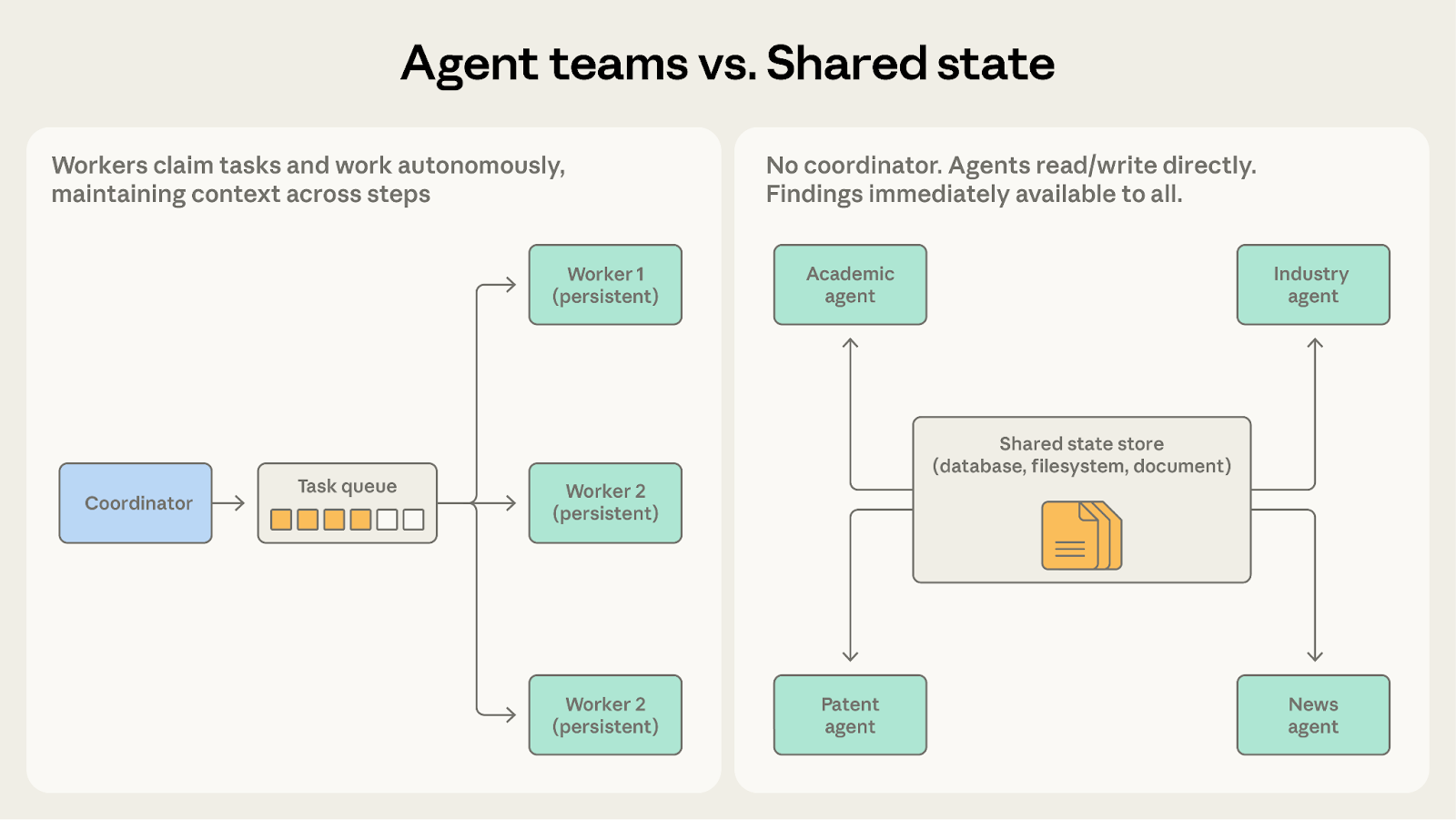
两者都涉及智能体自主运作。核心问题是:智能体是否需要彼此的发现?
- 选择智能体团队:当智能体在相互独立的分区上工作时。代码库迁移适合此模式——每个成员处理自己的服务,协调者最后汇总结果。
- 选择共享状态:当工作具有协作性、发现需要实时在智能体间流动时。研究综合系统更适合——学术智能体发现的关键研究人员,立即成为行业智能体调查的有效线索。
一旦成员需要相互沟通而不只是共享最终结果,共享状态会让这种沟通更加自然。
消息总线 vs. 共享状态
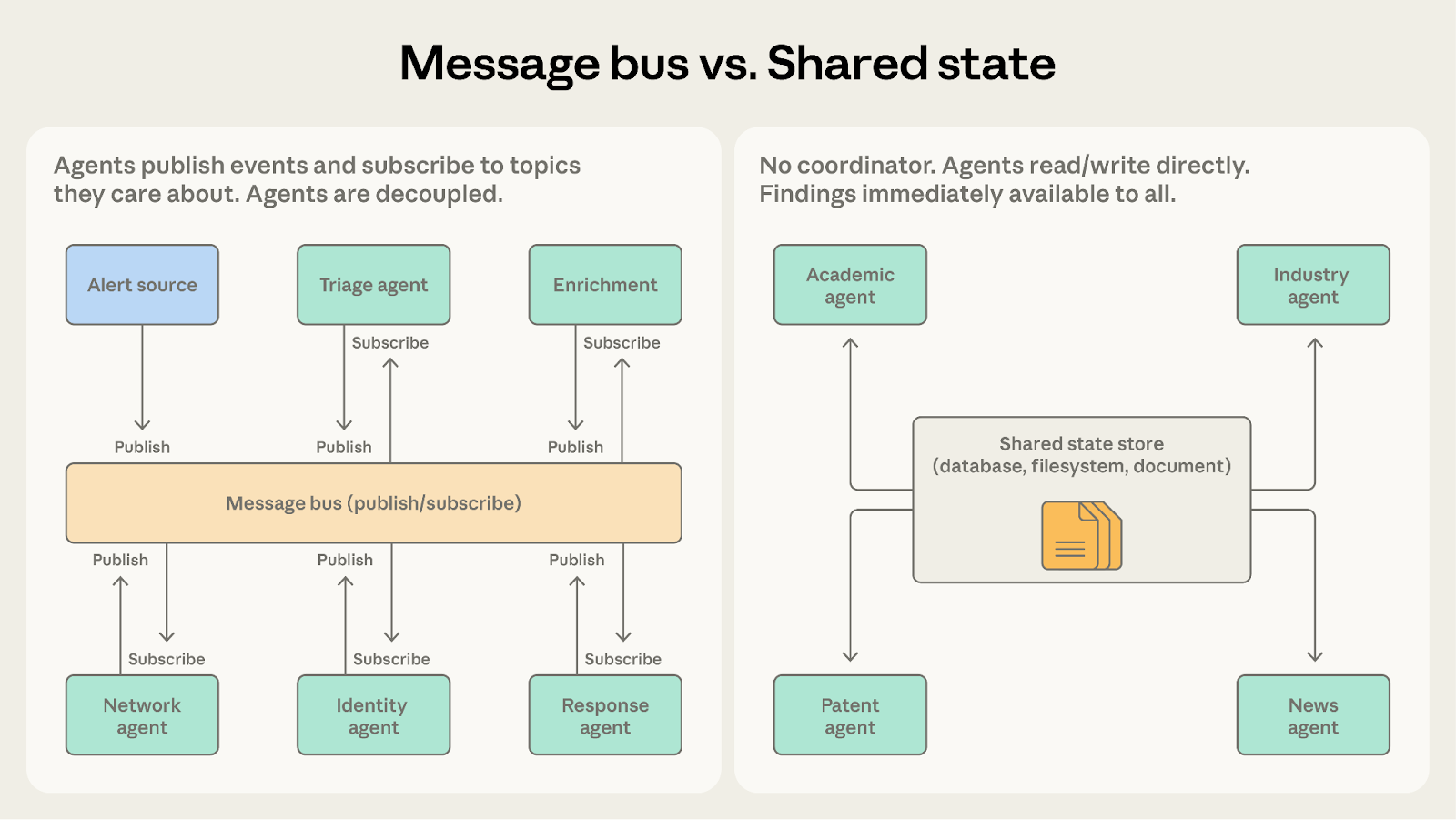
两者都支持复杂的多智能体协作。核心问题是:工作是作为离散事件流动,还是持续积累成共享知识库?
- 选择消息总线:当智能体对流水线中的事件做出响应时。安全运营系统按阶段处理警报,每个事件触发下一步——该模式在将事件路由给有能力的智能体方面非常高效。
- 选择共享状态:当智能体随时间积累发现、并在此基础上持续深入时。研究综合系统不断收集知识,智能体反复回到存储中查看他人成果并调整自己的调查方向。
消息总线仍然存在路由器这一中央组件。共享状态则是去中心化的。若消除单点故障是优先目标,共享状态能更彻底地实现这一点。
如果消息总线系统中的智能体发布事件是为了"分享发现"而非"触发行动",那么共享状态可能更合适。
入门建议
生产系统通常会混合使用多种模式。常见组合之一:用"编排者-子智能体"驱动整体工作流,对协作密集的子任务采用"共享状态";另一种:用"消息总线"做事件路由,每种事件类型由"智能体团队"风格的工作者处理。这些模式是构建块,而非互斥选项。
下表总结了各模式的适用场景。
对大多数用例,我们建议从"编排者-子智能体"起步。 它以最小的协调开销覆盖了最广泛的问题类型。观察它在哪里遇到瓶颈,再随着具体需求的浮现,有针对性地向其他模式演进。
在后续文章中,我们将通过生产实现与案例研究对每种模式进行深度拆解。关于多智能体系统何时值得投入的背景,请参阅 构建多智能体系统:何时以及如何使用它们。
致谢
本文由 Cara Phillips 撰写,Eugene Yang、Jiri De Jonghe、Samuel Weller 和 Erik S. 亦有贡献。