harness-managing-multiple-agents-anthropic
如何设计一个能够容纳未来各种harness框架和智能的系统?
如何扩展智能体管理:将"大脑"与"双手"解耦 随着模型能力不断提升,harness 中固化的各种假设会逐渐过时。 Managed Agents 是我们在 Claude Platform 上提供的托管服务,专为长周期智能体工作设计。它围绕一组稳定的接口构建——这些接口的目标,是尽可能不被任何具体实现所绑定,即便底层的 harness 在不断演进,接口本身也能保持稳定。
在 Anthropic 的工程博客里,有一个反复出现的主题:如何
构建高效的智能体 ,以及如何为
长周期任务 设计与优化
治理框架(harness) 。这些工作有一个共同点:
harness 往往把"Claude 自己做不到什么"这类假设,硬编码进了系统里。 但问题在于,这些假设必须被反复审视——随着模型能力持续进化,它们很容易像
《苦涩的教训》 里描述的那样,悄然过期,甚至反过来成为累赘。
举个具体例子:在之前的研究中我们发现,Claude Sonnet 4.5 在上下文接近窗口上限时,会倾向于提前"收尾"任务——这种行为有时被称为 "context anxiety(上下文焦虑)" 。为了应对这一问题,我们在 harness 里引入了上下文重置(context resets) 机制。然而,当我们把同一套 harness 迁移到 Claude Opus 4.5 时,发现这种焦虑行为已经不复存在——重置机制反而成了无效负担(dead weight) 。
我们预计,harness 会持续演进。因此,我们打造了 Managed Agents :一项代表你运行长周期智能体的托管服务,通过一小组接口对外暴露能力——这些接口的设计目标,是不被任何某个具体实现所绑定 (包括我们今天正在运行的实现)。
构建 Managed Agents,本质上是在解决计算机领域的一道经典难题:
如何为" 尚未被设想出来的程序 "设计系统。 几十年前,操作系统通过把硬件虚拟化为更稳定的抽象(例如进程、文件)解决了这个问题——这些抽象足够通用,因而能承载那些当时还不存在的程序。硬件可以换代,但抽象层始终稳定。
比如,read() 这个调用并不关心它读取的是 1970 年代的磁盘包,还是现代的 SSD。底层实现可以自由迭代,上层接口却长期不变。
Managed Agents 走的正是同样的路。
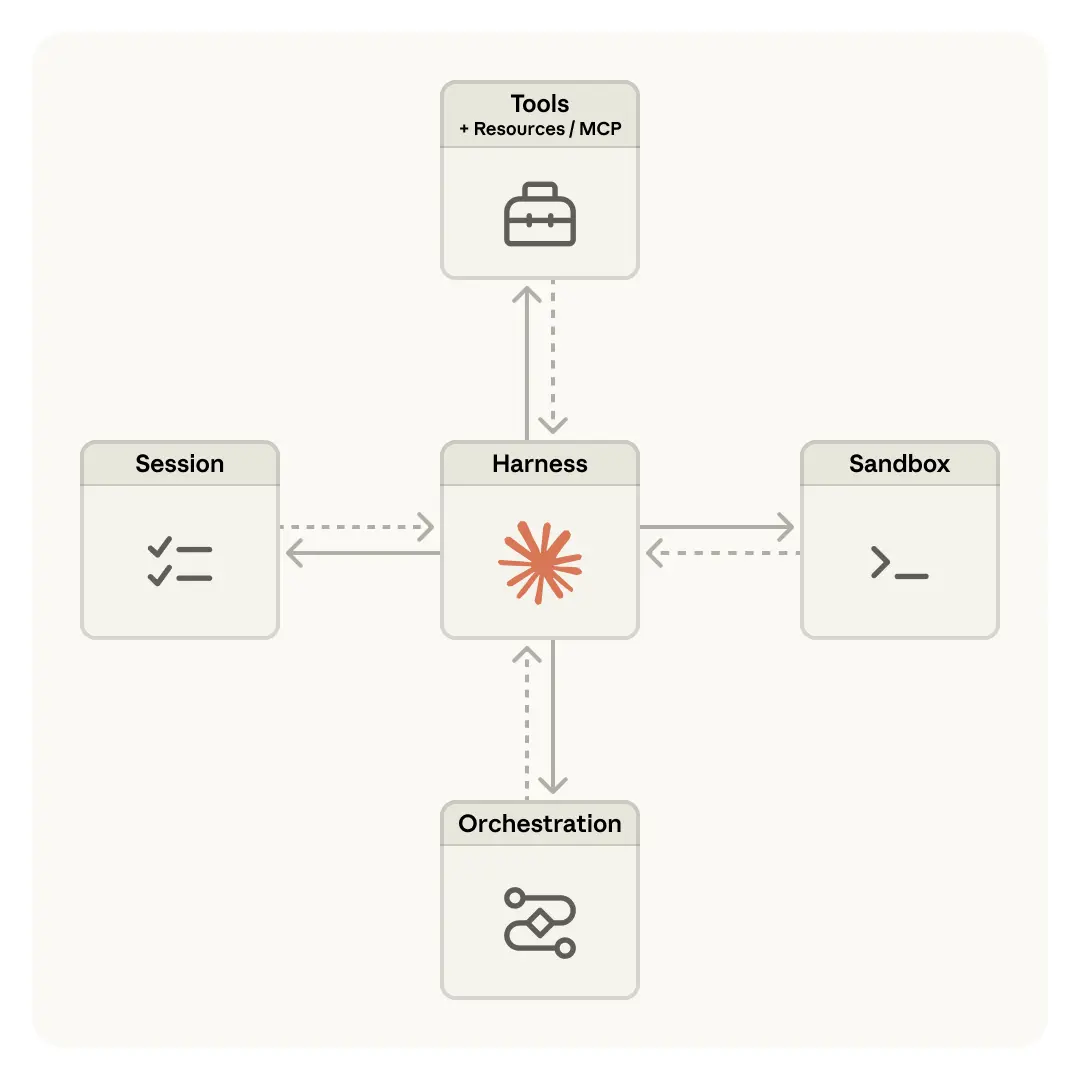
我们将智能体系统的关键组件虚拟化为三个抽象:
session(会话) :一份只追加(append-only)的日志,完整记录发生过的一切harness(治理框架) :循环调用 Claude、并将其工具调用路由到对应基础设施的那层逻辑sandbox(沙箱) :Claude 可以在其中运行代码、编辑文件的执行环境这样的拆分,使得每个组件的实现都可以独立替换,而不会影响其他部分。我们对接口的形态持有明确主张,但对接口背后跑的具体实现并不执着。
不要养"宠物" 最初的实现里,我们把所有智能体组件都放进同一个容器:session、agent harness 与 sandbox 共处同一个环境。
这种方式有一些优点,比如文件编辑可以直接通过系统调用(syscall)完成,服务之间也无需设计额外的边界。
然而,把所有东西耦合在一个容器里,很快让我们遭遇了一个经典的基础设施问题:
我们不小心养了一只 宠物 。 在"宠物 vs. 牛群(pets vs. cattle)"的比喻里:
在我们的场景里,这台服务器成了那只宠物:容器一旦故障,session 就会丢失;容器一旦卡死,我们就得设法把它"救活"。
而"救活容器"的过程,本质上就是在排查卡住的会话。我们能看到的只有 WebSocket 的事件流,但它无法告诉我们故障究竟发生在哪一层——harness 的 bug、事件流丢包、还是容器离线,表面症状几乎一模一样。
为了定位问题,工程师往往不得不进入容器打开 shell;但由于容器里通常包含用户数据,这种做法近乎于:我们根本没有一个安全可靠的调试手段。
第二个问题是,harness 默认假设 Claude 操作的资源就在容器旁边。当客户希望把 Claude 接入他们自己的 VPC 时,他们要么需要跟我们的网络做对等互联(peering),要么需要在自己的环境里部署我们的 harness。换句话说,一个写进 harness 的假设,在我们想接入不同基础设施时,就成了障碍。
将大脑与双手解耦 我们的解决方案,是把"大脑" (Claude + harness)、"双手" (sandbox 与执行具体动作的 tools),以及"会话" (session 事件日志)彼此解耦。
三者之间尽量少做假设,每个部分都可以独立失败、独立替换。
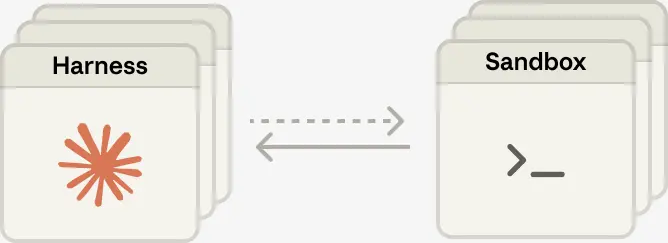
harness 离开容器。 解耦之后,harness 不再驻留在容器内部,而是以调用工具的方式来操作容器:execute(name, input) → string。
容器因此变成了"牛群":
容器挂了,harness 会将失败作为一次工具调用错误反馈给 Claude 如果 Claude 决定重试,便可按标准流程启动一个新容器:provision({resources}) 我们不再需要人工"照料"故障容器。
从 harness 故障中恢复。 harness 本身也因此变成"牛群"。
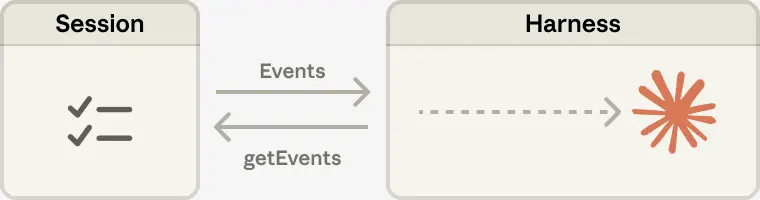
由于 session 日志存放在 harness 之外,harness 崩溃后无需保存任何状态。一个 harness 挂掉,可以立刻启动一个新的,通过 wake(sessionId) 重新接管,再用 getSession(id) 拉取事件日志,从上次中断的位置继续执行。
在智能体循环中,harness 通过 emitEvent(id, event) 将事件持续写入 session,维持一份持久且可追溯的完整记录。
安全边界。 在耦合架构里,Claude 生成的任何不受信任代码,都与凭证(credentials)运行在同一个容器中——这意味着一次提示注入攻击,只需说服 Claude 读取自己的环境变量,就可能拿到 token。
一旦攻击者获得这些 token,便可以启动新的、不受限制的会话,把任务继续委派下去。
缩小权限范围(narrow scoping)当然是一种缓解手段,但它同样是把"Claude 在有限 token 下做不到什么"这种假设固化进了系统——而 Claude 正在变得越来越强。
更结构化的修复思路,是确保 token 永远无法从 Claude 生成代码运行的 sandbox 中被触达 。为此,我们采用两种模式:
认证信息保存在 sandbox 外部的 vault 以 Git 为例:我们在初始化 sandbox 时用每个仓库的访问 token 完成 clone,并将 token 写入本地 git remote 配置。这样在 sandbox 内部可以直接 push / pull,而智能体本身始终无需接触 token。
对于自定义工具,我们支持 MCP,并将 OAuth token 存放在安全的 vault 中。Claude 通过一个专用代理调用 MCP 工具;该代理接收与 session 关联的 token,再从 vault 取回对应凭证去执行外部调用。harness 因此永远不需要了解任何凭证细节。
会话不等于上下文窗口 长周期任务往往会超出 Claude 的上下文窗口长度。解决这个问题的常见做法,通常都涉及一些不可逆的取舍:哪些信息保留,哪些丢弃。
compaction(压缩/整理) :让 Claude 将当前上下文保存成摘要memory tool(记忆工具) :把上下文写入文件,实现跨会话的持续学习context trimming(上下文裁剪) :选择性移除旧的工具结果或 thinking 块等占用 token 的内容但这种"选择性保留/丢弃"的不可逆决策,很容易导致失败:我们根本无法预知未来某一步究竟需要哪些 token。
如果消息在 compaction 步骤被转换,harness 会将压缩后的消息从 Claude 的上下文窗口中移除;而它们能否找回,取决于是否已被单独存储。
此前的一些研究(例如
这篇工作 )提出了一种思路:把上下文存储为一个
独立于上下文窗口之外的对象 ,让 LLM 可以通过编写代码对它进行过滤和切片来访问。
在 Managed Agents 中,session 提供了类似的效果:它让上下文成为一个存在于 Claude 上下文窗口之外 的独立对象。
但我们没有把它塞进 sandbox 或 REPL,而是选择将上下文以事件流的形式持久化 到 session 日志里。
接口 getEvents() 允许大脑对上下文进行"查询"——通过对事件流选取特定位置的切片来读取内容。这个接口非常灵活:
可以在某个关键时刻前倒回去读几条事件,查看前因后果 harness 还可以在把事件传入 Claude 上下文窗口之前,对这些事件做任意变换——包括为提升 prompt cache 命中率而进行的上下文组织,以及更通用的上下文工程处理。
我们将"可恢复的上下文存储"(session)与"任意的上下文管理"(harness)拆分开来 ,原因在于:我们无法预测未来模型需要怎样具体的上下文工程策略。接口只保证 session 是稳定、可用、可被检索的;至于如何组织与管理上下文,则完全交由 harness 决定。
更多的"大脑"与"双手" 更多的"大脑" 将大脑与双手解耦,还解决了早期客户最常反映的一个痛点:当团队希望 Claude 操作他们 VPC 内的资源时,过去唯一的办法是与我们的网络做对等互联(peering)——因为容器里的 harness 假设所有资源都在它旁边。
一旦 harness 离开容器,这个假设就自然消解了。
这一改动同样带来了性能收益。
最初把大脑放在单个容器里,意味着每多一个大脑,就要多启动一个容器。每个大脑在开始推理前,都必须等待容器完成 provision;每个 session 都要为容器启动支付一次性成本——即便这个 session 根本不需要用到 sandbox,也不得不提前 clone repo、启动进程、从服务器拉取待处理事件。
这段"空等待"直接体现在 TTFT(time-to-first-token) 上——从会话接受任务到输出首个 token 的等待时间,而这正是用户最敏感的延迟指标。
解耦之后,容器只在真正需要时,才由大脑通过一次工具调用来 provision :execute(name, input) → string。
因此,一个暂时不需要容器的 session,完全不必等待容器启动。推理可以在编排层从 session 日志拉取到待处理事件后立即开始。
采用这一架构后,p50 TTFT 下降约 60%,p95 下降超过 90% 。扩展到更多大脑,只需启动更多无状态的 harness;并且只在需要时,才将它们连接到具体的"双手"。
更多的"双手" 我们还希望:每个大脑可以连接到很多双手。
在实践中,这意味着 Claude 必须在多个执行环境之间进行推理,并决定把工作分发到哪里——相比只在单个 shell 里操作,这对模型的认知负担更高。早期模型尚不具备这种能力,所以我们起初才把大脑放在单个容器里。但随着智能提升,单容器反而成了瓶颈:一旦这个容器出问题,大脑正在触达的所有双手的状态都会受到波及。
将大脑与双手解耦后,每只手都成为一个工具:execute(name, input) → string——输入名称与参数,返回字符串。
这个接口可以承载任何自定义工具、任何 MCP server,以及我们自家的工具。 harness 不需要知道 sandbox 究竟是容器、手机,还是宝可梦模拟器。并且由于任何手都不再绑定某个特定的脑,大脑之间还可以互相传递与共享这些手。
结语 我们面对的挑战其实古已有之:如何为"尚未被设想出来的程序"设计系统。
操作系统之所以能沿用几十年,是因为它将硬件虚拟化为足够通用、足够稳定的抽象,从而得以承载那些当时还不存在的程序。
在 Managed Agents 中,我们同样希望打造一套能够容纳未来各种 harness、sandbox 或其他组件演进的系统,同时围绕 Claude 保持稳定。
从某种意义上说,Managed Agents 是一种 meta-harness(元 harness) :它并不执着于未来 Claude 必须使用的某种具体 harness 形态,而是通过一组通用接口,让各种 harness 都能被接入。
例如,Claude Code 是我们广泛使用的一种优秀 harness;我们也看到,面向特定任务的 harness 在窄域上往往表现更强。Managed Agents 的目标,是随着 Claude 能力的持续提升,始终能容纳这些不同的实现形态。
所谓 meta-harness 设计,就是在 Claude 周边的接口上保持明确主张:
Claude 需要能扩展到 many brains 与 many hands 我们设计这些接口,是为了让系统在长时间尺度上可靠、安全地运行;同时不对未来需要多少脑、多少手,或它们身处何处做任何预设。
致谢 作者:Lance Martin、Gabe Cemaj、Michael Cohen。
感谢 Nodir Turakulov 和 Jeremy Fox 就这些话题提供的宝贵交流;特别感谢 Agents API 团队以及 Jake Eaton 的贡献。

AnthropicAIScaling Managed Agents: Decoupling the brain from the hands