Created time
Apr 13, 2026 03:04 PM
category
library
date
Apr 9, 2026
status
Published
icon
password
slug
for-advisor-strategy-opus-sonnet-smart-injection
type
post
likes
views
summary
如何通过顾问策略,利用 Opus 提升 Sonnet 的智能水平并降低使用成本?
tags
OpenAI
工程实践
Agent
原文链接:https://claude.com/blog/the-advisor-strategy 发表日期:2026年4月9日
顾问策略:用 Opus 为 Sonnet 注入智能
越来越多的开发者发现了一种在智能水平与使用成本之间取得更优平衡的方法,我们将其称为"顾问策略":以 Opus 担任顾问,搭配 Sonnet 或 Haiku 作为执行者。这一组合能让你的智能体接近 Opus 级别的推理能力,同时将运行成本控制在 Sonnet 的量级。
今天,我们正式在 Claude 平台推出顾问工具(advisor tool)——只需在 API 调用中改动一行代码,即可启用顾问策略。
用顾问策略打造高性价比智能体
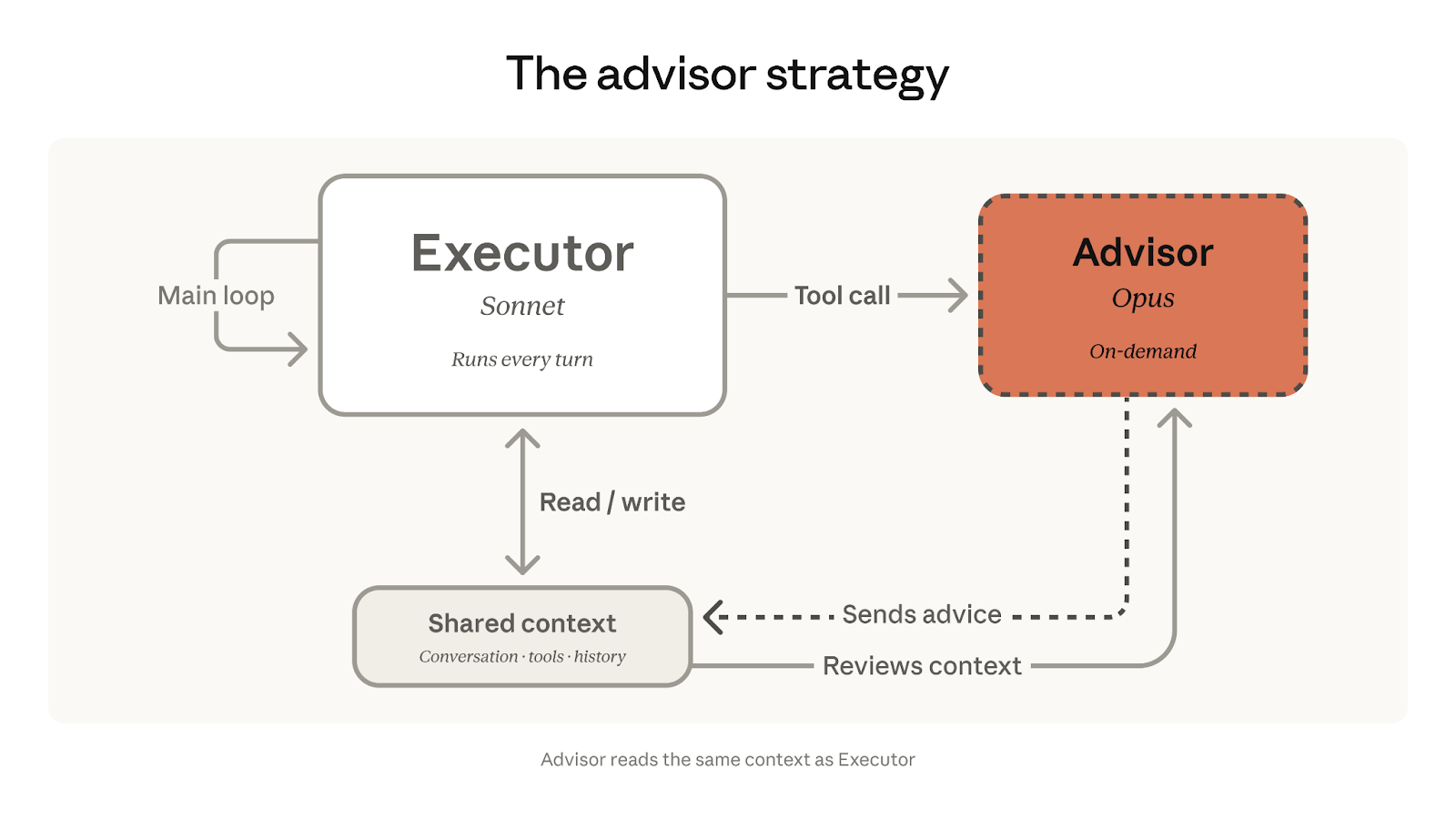
在顾问策略中,Sonnet 或 Haiku 作为执行者,全程端到端地驱动任务——调用工具、读取结果、持续迭代,直至找到解决方案。当执行者遇到难以独立判断的决策节点时,便会向 Opus 发起咨询。Opus 访问共享上下文后,返回行动计划、修正建议,或发出停止信号,随后执行者继续推进。顾问始终不调用工具、不生成面向用户的输出,只为执行者提供方向性指引。
这与常见的"大模型编排小模型"子智能体模式恰好相反——后者由大型编排模型拆解任务、分派给小型工作模型。在顾问策略中,一个更小、更经济的模型负责全程驱动与任务升级,无需任务分解、无需工作池、也无需编排逻辑。前沿级推理能力只在执行者真正需要时才介入,其余环节均维持在执行者的成本水平。
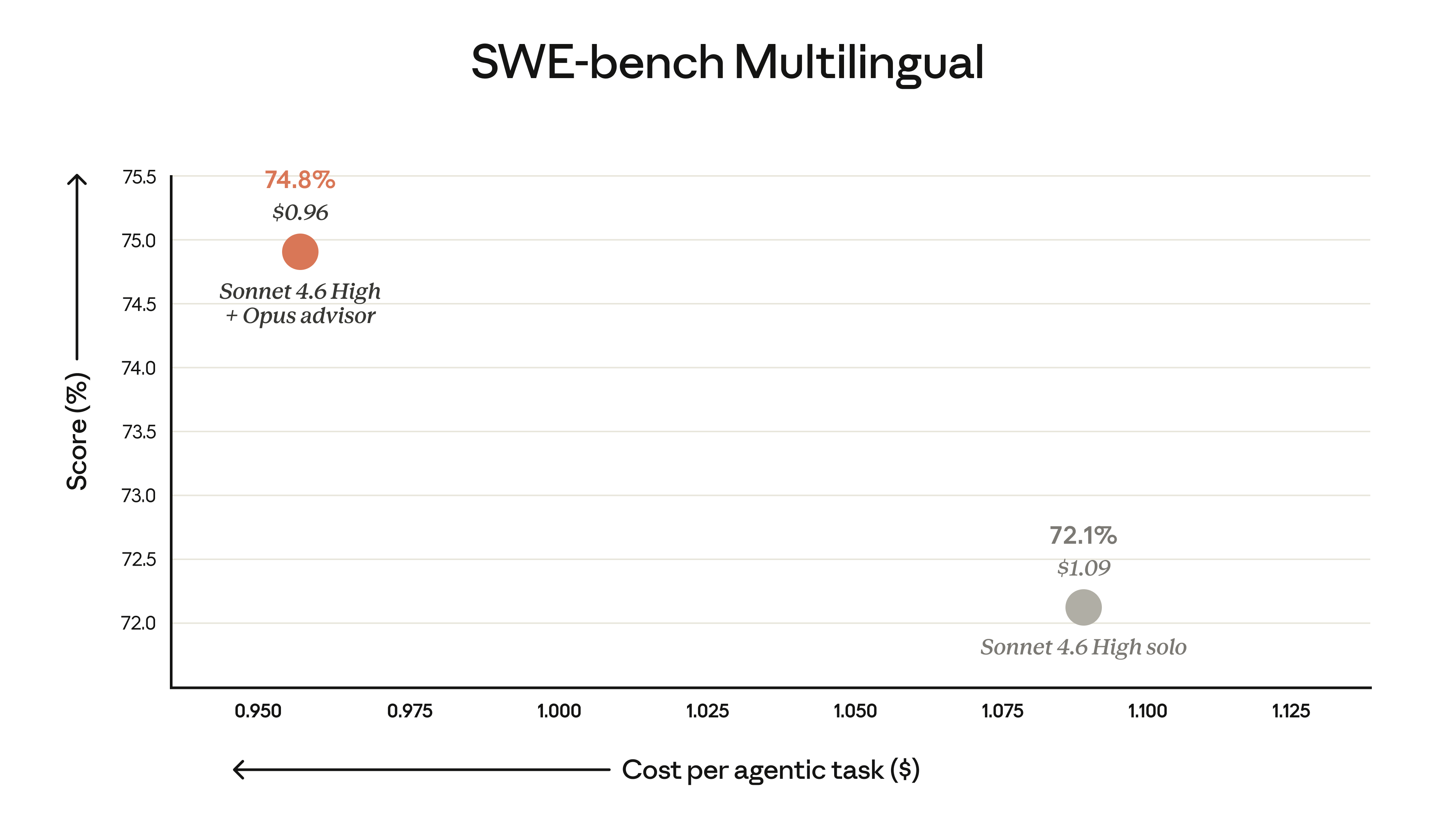
在我们的评估中,以 Opus 为顾问的 Sonnet 在 SWE-bench Multilingual 上的得分比单独使用 Sonnet 提升了 2.7 个百分点,同时每个智能体任务的成本降低了 11.9%。
顾问工具
我们通过 顾问工具 将顾问策略引入 API。这是一个服务端工具,当 Sonnet 或 Haiku 需要指引或协助完成特定任务时,会自动调用它。
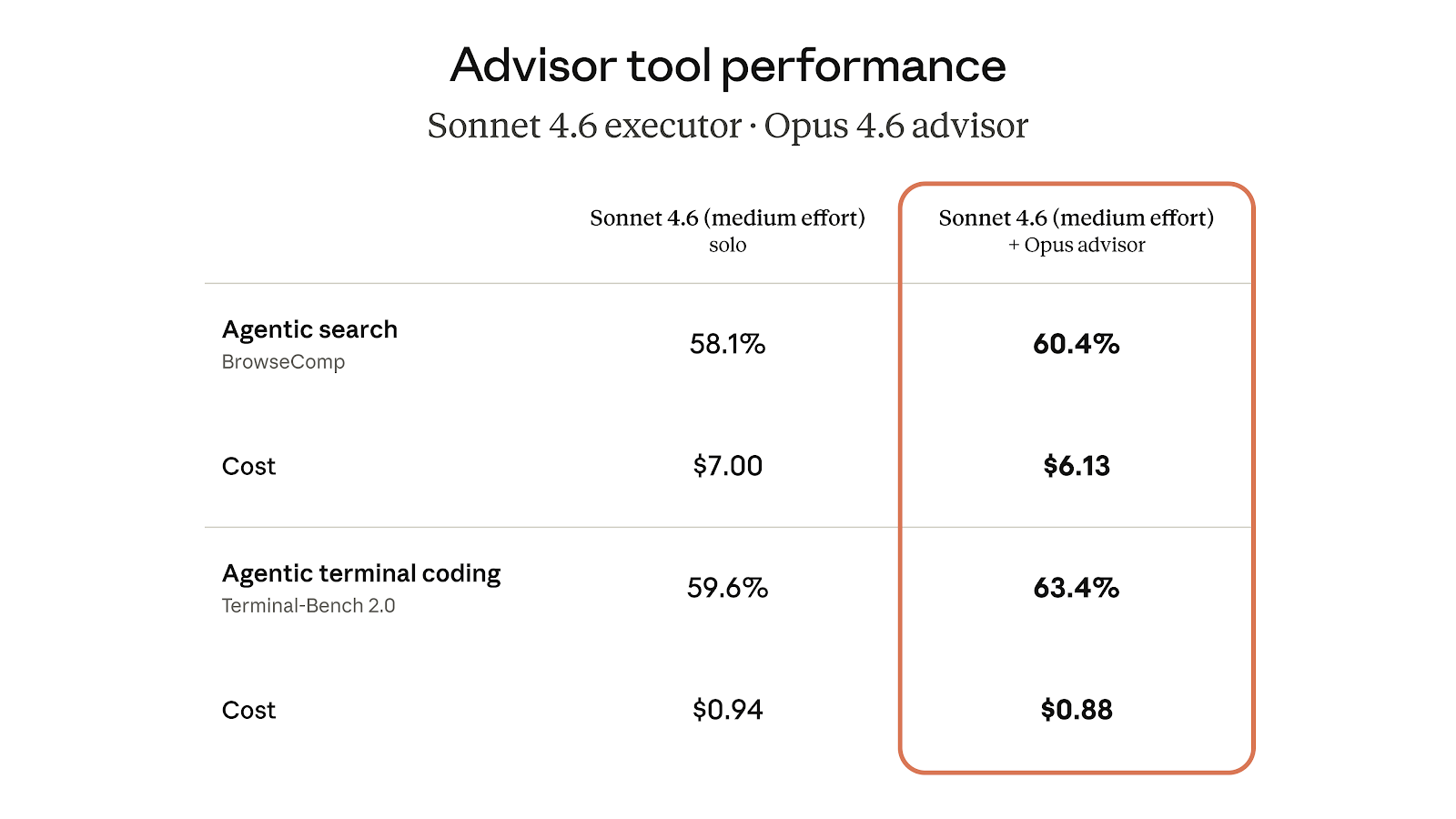
在我们的评估中,配备 Opus 顾问的 Sonnet 在 BrowseComp 和 Terminal-Bench 2.0 基准测试中均有得分提升,且单任务成本低于单独使用 Sonnet。
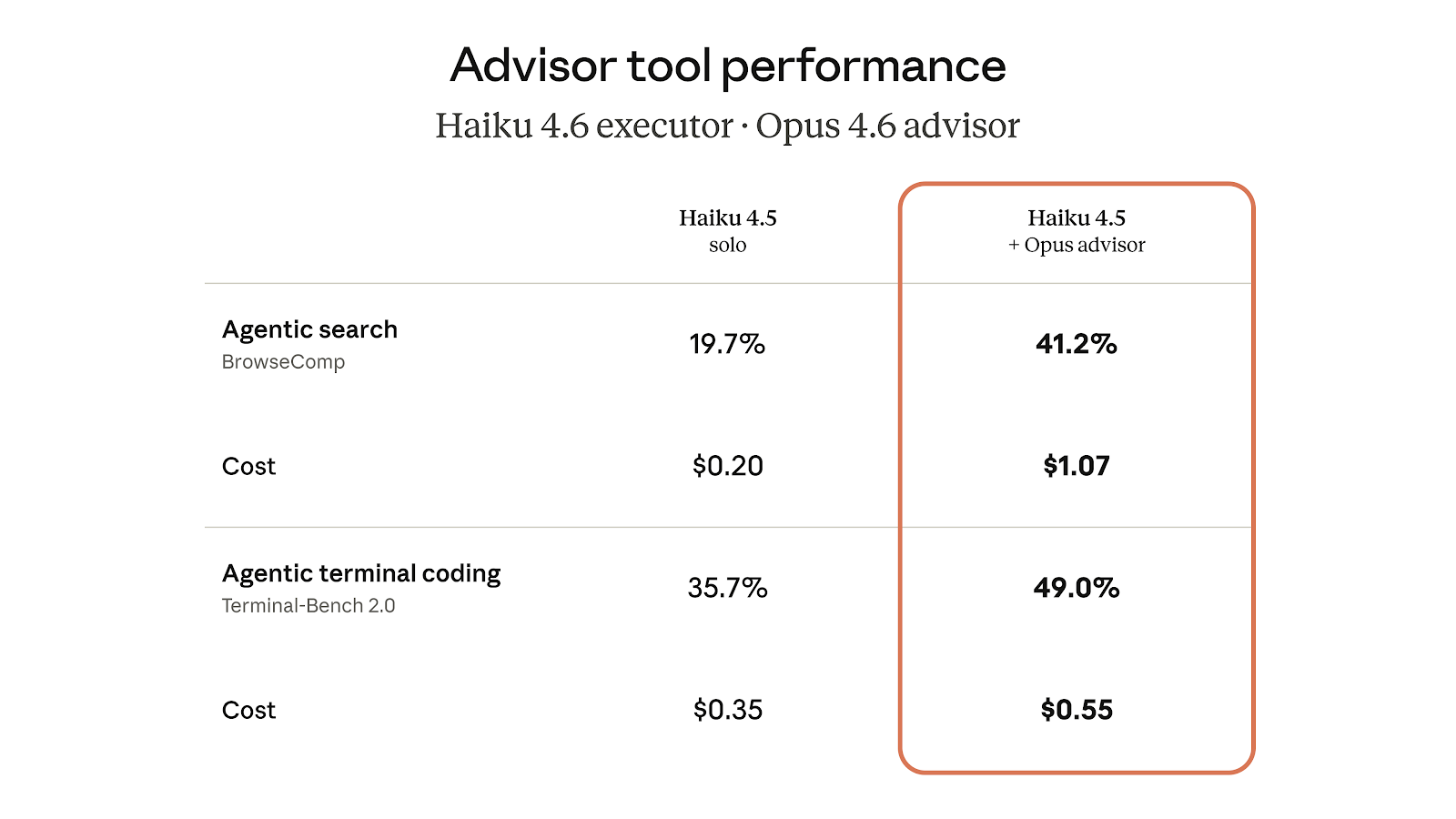
顾问策略同样适用于以 Haiku 为执行者的场景。在 BrowseComp 测试中,配备 Opus 顾问的 Haiku 得分达到 41.2%,超过其单独得分(19.7%)的两倍。虽然较单独使用 Sonnet 仍低 29%,但每任务成本下降了 85%。顾问的引入会相对提高 Haiku 单独运行的成本,但总价格依然只是 Sonnet 的一小部分——对于需要在智能与成本间精细权衡的高频任务而言,这是极具吸引力的选择。
在你的 Messages API 请求中声明
advisor_20260301,模型切换将在单个 /v1/messages 请求内完成——无需额外往返通信,无需手动管理上下文。由执行者模型自主决定何时调用顾问;一旦调用,我们会将经过整理的上下文路由给顾问模型,顾问返回计划后,执行者在同一请求内继续工作,全程无缝衔接。定价:顾问 token 按顾问模型费率计费,执行者 token 按执行者模型费率计费。由于顾问只输出简短的计划(通常为 400–700 个文本 token),而执行者以更低费率处理全部输出,整体成本远低于端到端运行顾问模型。
内置成本管控:通过
max_uses 限制每个请求中顾问的最大调用次数;顾问 token 在 usage 模块中单独报告,便于分层追踪支出。开始使用
顾问工具现已在 Claude 平台以测试版形式上线。快速上手步骤:
- 添加测试版功能头:
anthropic-beta: advisor-tool-2026-03-01
- 在 Messages API 请求中声明
advisor_20260301
- 根据你的使用场景调整系统提示词
建议针对以下三种配置运行你现有的评估套件:单独使用 Sonnet、Sonnet 执行者 + Opus 顾问、单独使用 Opus。更多详情请参阅官方文档。
脚注
- SWE-bench Multilingual:Sonnet 4.6 单独运行时开启了自适应思维;Sonnet 4.6 + 顾问使用了我们建议的编码系统提示词,并关闭了思维功能。两次运行均使用了高强度的 bash 与文件编辑工具。分数为九种语言、300 道题目的五次试验均值。所有运行均以 Opus 4.6 作为顾问模型。
- BrowseComp:所有运行均关闭思维功能,使用网页搜索与网页抓取工具。Sonnet 4.6 运行使用中等强度;Sonnet 4.6 + 顾问采用了我们建议的编码系统提示词,Haiku 4.5 + 顾问则未使用。无程序化工具调用,无上下文压缩。分数基于 1,266 道题目的单次尝试。所有运行均以 Opus 4.6 作为顾问模型。
- Terminal-Bench 2.0:所有运行均关闭思维功能,使用 bash 与文件编辑工具。Sonnet 4.6 运行使用中等强度;两次顾问运行均未采用我们建议的编码系统提示词。每个任务在独立 pod 中运行,分配 3 倍资源与 1 倍超时时间。分数为 89 个任务每任务五次尝试的均值。所有运行均以 Opus 4.6 作为顾问模型。