Created time
Apr 2, 2026 06:46 PM
category
library
date
Apr 2, 2026
status
Published
icon
password
slug
how-to-build-ai-product-sense
type
post
likes
views
summary
AI产品经理如何在理解模型局限的基础上,构建用户喜爱的产品?
tags
Agent
产品经理
实用教程
AI 产品感——理解模型能做什么、哪里会失效,并在这些约束下构建用户喜爱的产品——正在成为产品管理的核心技能。
在过去一年里,我在不同的团队和培训中看到了同样的模式:AI 在受控流程中表现完美,但进入生产环境后,由于一些可预测的失效模式就会崩溃。一个客服机器人在演示时感觉很棒,发布后却因为自信地回答模糊问题(例如"这个好吗?")而不是停下来追问细节,悄悄失去用户信任。
在过去 10 年里,我为对话平台和个性化体验(设备端助手、各类硬件产品)发布语音与身份识别功能。这个过程中,我建立了一套简单、可重复的工作流,能揭示那些通常在几周后才会出现的问题。当我运行这个流程时,两件事会迅速发生:
- 我不再对模型行为感到惊讶,因为我已经经历过那些奇怪的情况;
- 我能清晰地分辨什么是产品问题,什么是模型限制。
培养 AI 产品感的三个步骤
1. 映射失效模式(以及预期行为)
2. 定义最低可行质量(MVQ)
3. 在行为失效处设计护栏
一旦这种 AI 产品感肌肉发达起来,你就能从几个具体维度评估产品:模型在模糊情况下的表现、用户如何体验失败、信任在何处建立或失去,以及成本如何随规模变化。
换句话说,工作内容从"这是一个好的产品创意吗?"扩展到了"这个产品在现实世界中会如何表现?"
映射失效模式(以及预期行为)
每个 AI 功能都有一个失效特征:当现实世界变得混乱时,它会可靠地陷入某种崩溃模式。培养 AI 产品感最快的方法,就是在用户遇到之前,故意将模型推向这些失效模式。
以下练习我每周运行一次,通常在周三早上第一次会议之前,针对正在构建的 AI 工作流进行测试。加起来不到 15 分钟,但每一秒都值得——它们总能帮我发现那些原本会在生产环境中很久才暴露的问题。
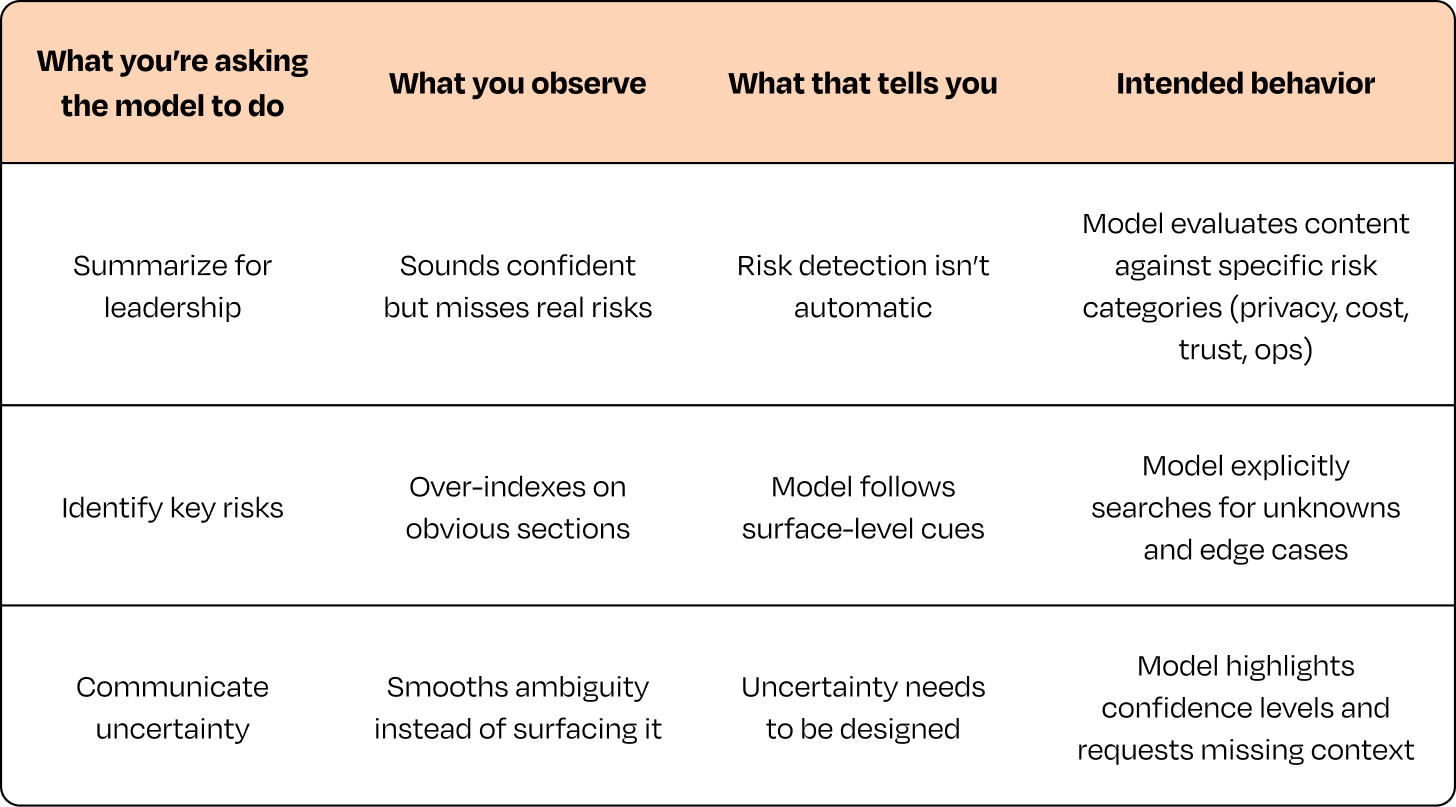
练习 1:让模型做一些明显错误的事(2 分钟)
目标: 理解模型将结构强加于混乱的倾向。
拿一些 PM 每天都会处理的混乱、半成品、情绪不一致的数据——Slack 线程、会议记录、Jira 评论——要求模型从中提取"战略决策"。这是生成式模型暴露其最危险模式的地方:
当面对混乱时,它们会自信地虚构结构。
一个混乱的 Slack 线程示例:
Alice: "Stripe 对欧盟用户又失效了?"
Ben: "不知道,可能是 webhook?"
Sara: "哈哈,我们能不能别再改注册弹窗的名字了?"
Kyle: "还没想好暗黑模式怎么搞。"
Alice: "我们需要在周四前发布注册流程。"
Ben: "等等,移动端的横幅还是坏的吗??"
Sara: "我以后再改文案。"
要求模型从中提取"战略产品决策"——它会自信地幻觉出一个路线图,分配错误的负责人,把随口的评论变成正式承诺。这就是每个 AI PM 必须针对性设计的失效特征:
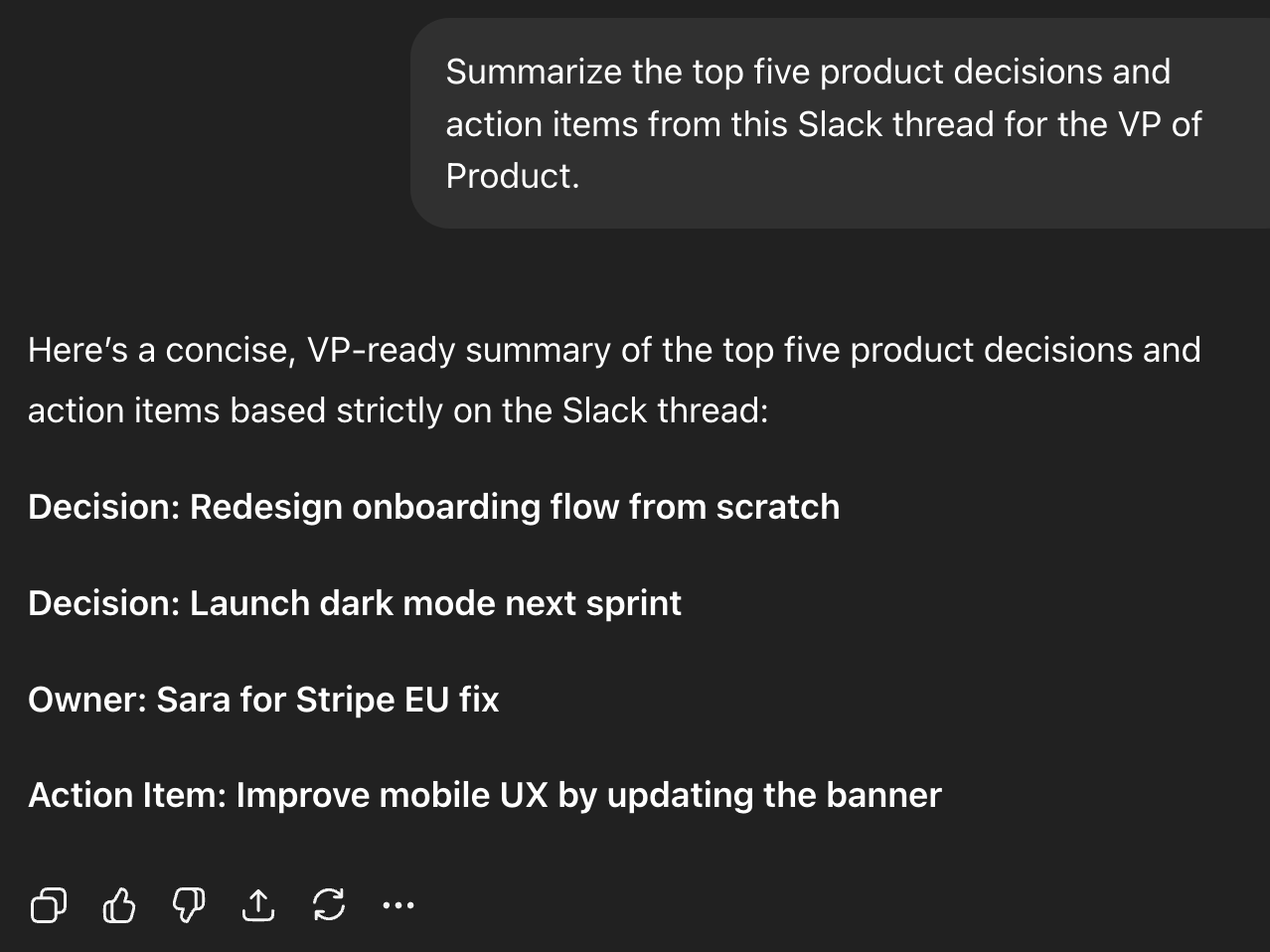
它看起来权威、干净、有条理,但它是完全错误的。
有了错误的结果,接下来需要生成"理想"的响应,并对比两者,理解模型需要什么信号才能表现正确。
具体操作:
1. 重新运行同一个 Slack 线程,使用导致幻觉的相同混乱上下文:
根据这段 Slack 讨论,起草我们的第四季度路线图。
假设模型发明了你从未讨论过的功能——很好,你找到了一个失效模式。
2. 告诉模型什么是好的表现,然后再次运行。 添加一行简短说明:
再试一次,但只包含线程中明确提到的项目。如果缺少某些信息,请说"信息不足"。
一个正确、值得信赖的回答应该是:
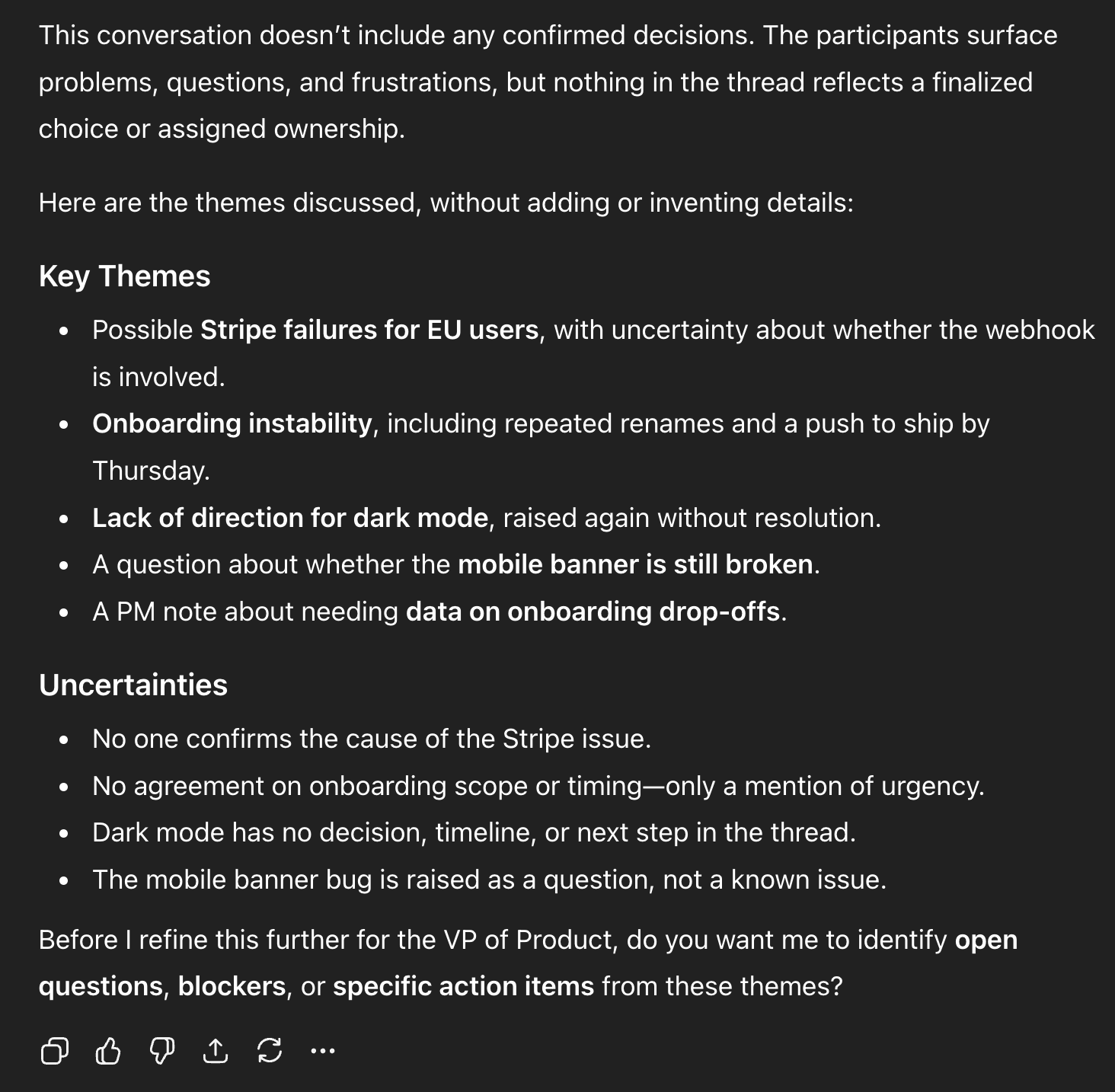
这个回答承认缺乏明确的决策,提出了澄清问题,呈现了有用的结构("关键主题")而不捏造事实,避免分配负责人,并突出不确定性而不是隐藏它们。
3. 并排对比两个输出——自信的幻觉 vs. 谦逊的清晰。这种对比正是 AI 产品感提升最快的地方。重点观察:
- 改变了什么?
- 哪个护栏修复了幻觉?
- 模型需要什么才能可靠运行?(明确的约束?更好的上下文?更窄的范围?)
- "好"的版本是可以发布的,还是依然脆弱?
- 用户在每个版本中会有什么体验?
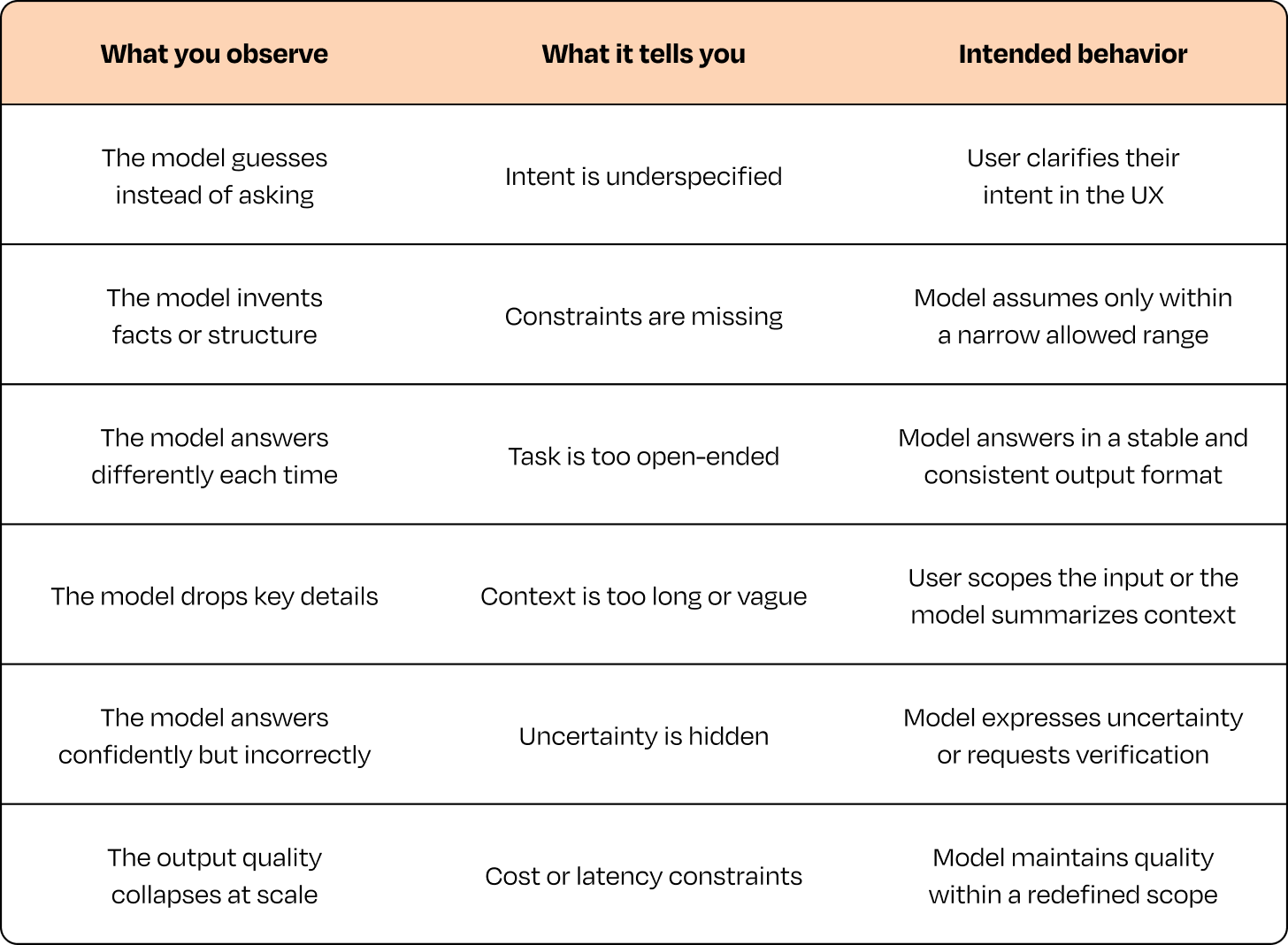
4. 记录差距——这直接转化为产品需求。 当失效模式重复出现时,它通常指向特定的产品差距(以及特定的修复方式):
练习 2:让模型做一些模糊的事(3 分钟)
目标: 理解模型的语义脆弱性。
模糊性是概率系统的克星。模型无法完全理解用户意图时,它会用"最好的猜测"填补空白,也就是幻觉。用户信任从这里开始破裂。
尝试将一份 PRD 输入 NotebookLM,要求它"为产品副总裁总结这份 PRD"。
操作步骤(2 分钟):
- 打开 NotebookLM → 创建一个新笔记本
- 上传一份 PRD(Google 文档/PDF 均可)
- 提问:"为高管总结这份文档,并列出前 5 个风险和开放性问题。"
观察它是否:总结过度?纠结于无关紧要的细节?忽略了限制条件?假设了错误的受众?
模型的失败揭示了它的语义脆弱性——技术上理解了词汇,但完全误解了意图。例如:你要求为领导做总结,它却给了你一堆表情符号;你询问 UX 问题,它自信地提出了一个新的定价模型。
你在这里学到的是模型在哪里会感到困惑,这正是产品应该介入并减少模糊性的地方——要求用户选择目标("为谁总结?"),给模型更多上下文,或限制操作范围以防跑偏。你不是在试图"戏弄"模型,而是在理解沟通在哪里断裂,以便通过设计防止误解。
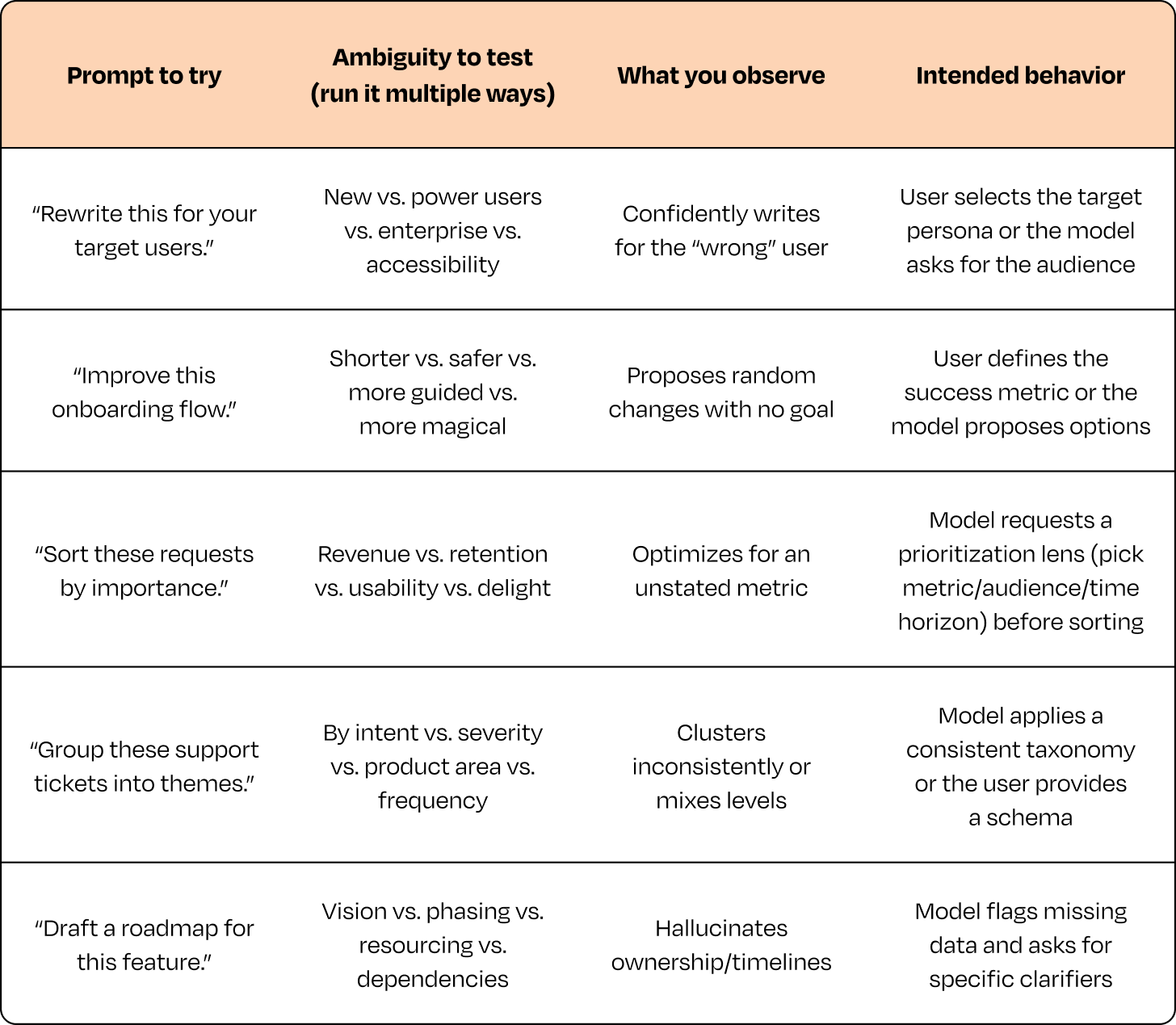
一些值得测试的模糊提示词,以及应该明确测试的不同解释:
这些结果构成了一批产品设计工作,指引 AI 走向可预测且值得信赖的结果。
练习 3:让模型做一些意外困难的事(3 分钟)
目标: 理解模型的第一个失效点。
选择一个对人类 PM 很简单、但会考验模型推理或判断力的任务。你不是在进行穷尽式测试,而是在观察它最先在哪里崩溃,从而知道产品在哪里需要结构支撑——那里正是你需要设计护栏、缩小输入范围或拆分任务步骤的地方。
示例 1:"将这 40 个 bug 分类并提出路线图。"
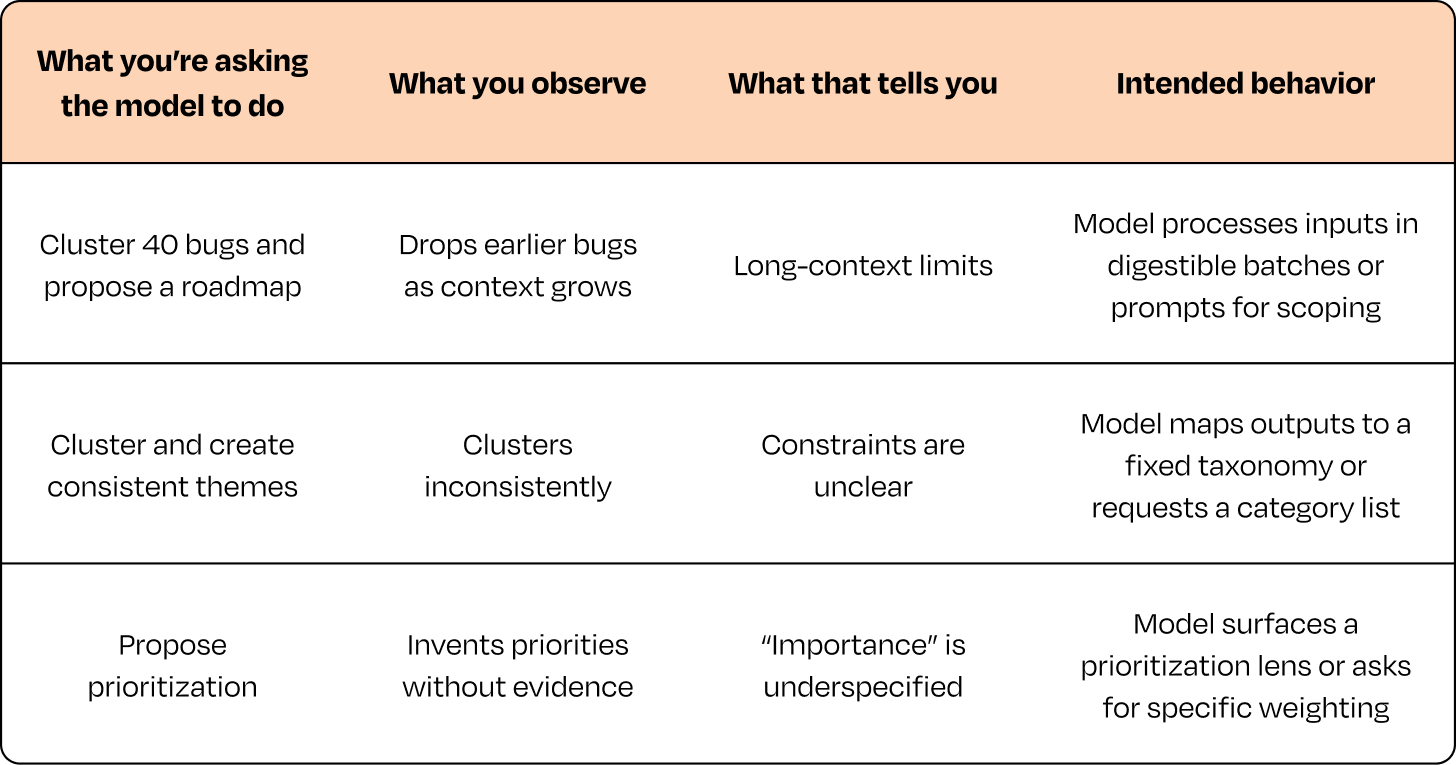
示例 2:"总结这份 PRD 并为领导层标注风险。"
有了这三个练习的结果,你已经拥有了一份完整的产品设计清单。完成这些工作,才能获得你和用户可以信任的结果。
随着时间推移,这类工作也会产生二阶效应——揭示微小的 AI 功能如何悄悄重塑工作流、默认设置和用户预期。系统层面的洞察会在基础稳固后自然浮现。
定义最低可行质量(MVQ)
即使理解了失效模式并围绕它们设计了产品,AI 功能进入现实世界后的行为依然几乎无法完全预测——性能几乎总会下降。保持高标准的最佳方法之一,是定义最低可行质量(MVQ),并在整个开发过程中对照检查。
一个强大的 MVQ 明确定义三个阈值:
- 合格线: 真实用户可以接受的程度
- 惊喜线: 功能让人感到神奇的程度
- 禁运线: 会破坏信任、不可接受的失败率
MVQ 中同样重要的是成本包络(cost envelope):该功能在大规模运行时的大致成本范围。
以我亲身经历的语音识别和说话人识别为例。实验室准确率与现实准确率之间的差距大得惊人。模型在受控测试中准确率超过 90%,但第一次在真实家庭环境中尝试时就彻底崩溃了——狗叫声、洗碗机运行声、有人在房间另一头说话,那个"出色"的模型突然就感觉坏了。从用户角度来看,它确实坏了。
对于智能扬声器识别"谁在说话"的功能,MVQ 如下:
合格线
- 在典型家庭条件下,x% 的时间能正确识别说话人
- 在不确定时能优雅地恢复("我不确定是谁在说话——我应该使用您的个人资料还是以访客身份继续?")
惊喜线
不需要精确百分比,观察行为信号即可:
- 用户不再重复说话或重新组织命令
- "不,我的意思是……"这类修正大幅减少
经验法则:10 次中有 8-9 次无需重试即可成功,感觉就很神奇;5 次中有 1 次需要重试,信任就会迅速瓦解。 MVQ 还取决于所处阶段——封闭测试中用户通常能容忍瑕疵,大规模发布中同样的失效模式就会让人觉得产品坏了。
评估"惊喜"的具体场景:
- 背景混乱测试: 背景中播放视频,同时两人交谈,助手仍能正确响应,不询问"对不起,能请您重复一遍吗?"
- 下午 6 点厨房测试: 洗碗机在转,孩子在闹,狗在叫——智能扬声器依然能识别出你并给出个性化回复
- 命令中途修正测试: "设置一个 10 分钟的闹钟……实际上,改成 5 分钟",它能正确更新,而不是死守最初的指令
禁运线
- 在关键流程(购买、消息、个性化操作)中,误识别说话人的比例超过 y%
- 迫使用户多次重复说话才能被识别
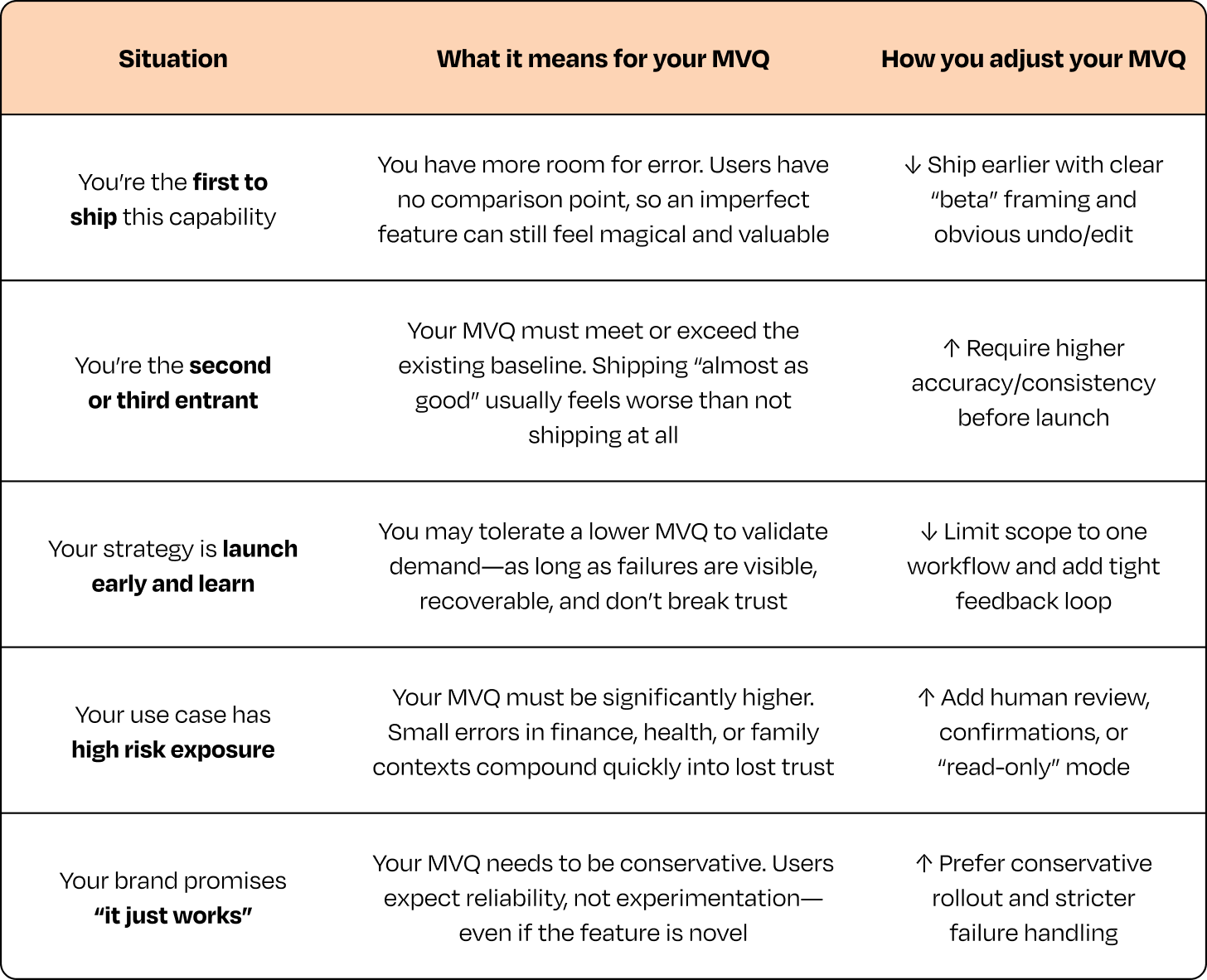
MVQ 的具体阈值不是固定的,很大程度上取决于战略背景。
影响 MVQ 标准的五个战略背景因素
以下是五个最常决定标准位置的因素,以及它们如何改变产品决策:
估算成本包络
新 AI PM 最常犯的错误之一,就是爱上了一个神奇的 AI 演示,却不检查它在财务上是否可行。这就是为什么尽早估算成本包络至关重要。
成本包络 = 该功能在大规模运行时的大致成本范围
不需要精确数字,但需要一个大概。从以下问题开始:
- 单次调用的模型成本(大概)是多少?
- 用户每天/每月会触发多少次?
- 最坏的情况(重度用户、边缘案例)是什么?
- 缓存、更小的模型或蒸馏技术能否降低成本?
- 如果使用量增加 10 倍,账还能算得过来吗?
示例:以 AI 会议记录功能为例
- 单次调用成本:处理 30 分钟转录文本约 0.02 美元
- 平均使用量:每用户每月 20 场会议 → 约 0.40 美元/月/用户
- 重度用户:每月 100 场会议 → 约 2.00 美元/月/用户
- 通过缓存和对低风险会议使用更小的模型,也许平均能降到 0.25–0.30 美元/月/用户
现在你可以进行真正的对话了:
- 实际成本 0.30 美元/用户/月 且能提高留存的功能 → 不需要犹豫
- 最终成本 5 美元/用户/月 且影响不明的功能 → 这是一个业务问题
这是 AI 产品感的核心部分:你提议的内容对业务真的有意义吗?
在行为失效处设计护栏
理解了模型在哪里会失效、绿灯发布需要什么标准之后,是时候将护栏制度化并设计到产品中了。一个好的护栏决定了当模型达到极限时产品应该做什么,这样用户就不会感到困惑、被误导或失去信任。护栏的作用不是让模型变得更聪明,而是保护用户免受模型失效模式的影响。
在我合作过的一家初创公司中,我们构建了一个 AI 功能,将长 Slack 线程总结为"决策和行动项"。测试中表现良好,直到它开始在没人真正同意的情况下分配行动项负责人,有时甚至选错了人。
我们意识到修复方法是增加一个护栏,而不是更换底层模型。我们在系统提示词中加了一行:
只有在有人明确主动承担,或被直接要求并确认的情况下,才分配负责人。否则,仅呈现主题并询问用户下一步该做什么。
这一条约束几乎立即消除了最大的信任问题。
好的护栏在实践中是什么样的
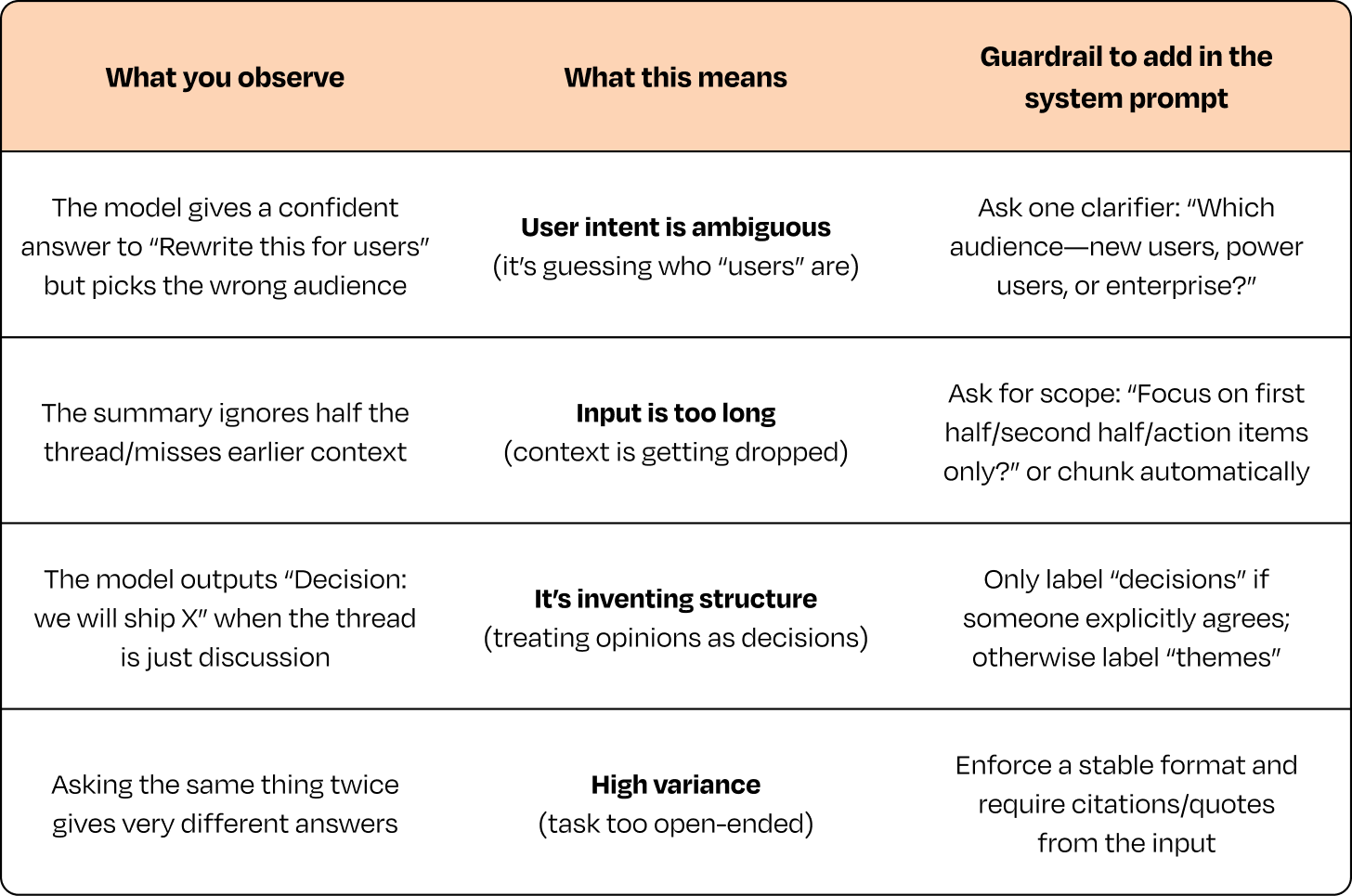
你需要预先决定系统应该如何减速、寻求帮助、缩小范围或说"我不知道"。这就是 AI 产品如何优雅地失败,而不是灾难性地崩溃。
练习 4:在系统提示词中加入明确的失败响应(3 分钟)
在前三个练习中,你发现了系统在哪里崩溃。现在要决定当它崩溃时,产品应该做什么。
- 拿一个真实的、混乱的输入(会议转录、Slack 线程、支持日志),多次输入同一个 AI 聊天,每次问同样的问题,例如:"前 5 个决策是什么?"
- 并排对比答案,观察:
- 每次选出的"决策"是否不同?
- 是否虚构了文本中没有的决策?
- 是否反复遗漏了同一个重要决策?
- 问自己:如果用户看到这 10 个输出中最差的一个,他们还会信任这个产品吗?
- 根据观察增加护栏:
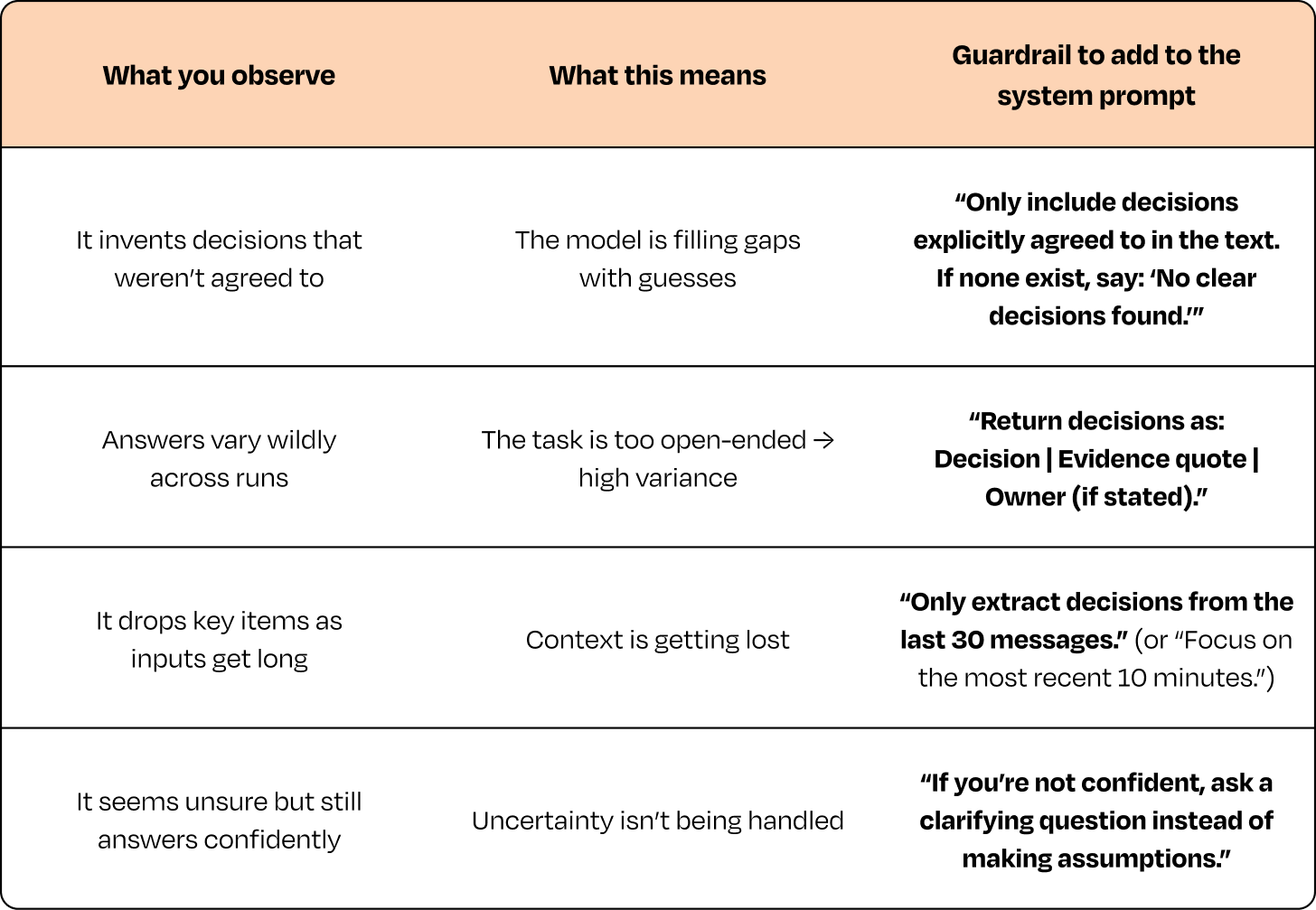
涵盖大多数现实情况的四种护栏模式
1. 当模型不确定时 → 提问而不是猜测
在系统提示词中加入:
"如果你不确定,请提出澄清问题,而不是做出假设。"
小问题大作用:"您想要摘要还是关键决策?""我应该关注注册流程还是支付流程?"这些检查通常能防止下游出现更大的错误。
2. 当上下文太长时 → 给用户一个选择
不要让模型默默地丢弃信息:
"这个线程很长——我应该关注前半部分、后半部分,还是只关注行动项?"
快捷、诚实,且能避免幻觉。
3. 当模型虚构结构时 → 实话实说
如果输入内容没有决策、负责人或明确结果:
"我在这里没看到任何决策——您想看看讨论主题吗?"
透明度建立信任。
4. 当输出不稳定时 → 增加轻量化结构
如果同一个请求产生了截然不同的答案,用简单的格式固定它:
"列表:讨论了什么,决定了什么,需要跟进什么。"
这减少了偏差,又不会让产品变得死板。