Created time
Apr 2, 2026 05:08 PM
category
library
date
Apr 1, 2026
status
Published
icon
password
slug
for-caching-experiences-in-claude-code
type
post
likes
views
summary
如何有效利用提示词缓存来优化智能体的性能?
tags
Claude
工程实践

工程界有句老话——"缓存规则一切"(Cache Rules Everything Around Me)。这条准则在智能体(Agent)领域同样成立。
像 Claude Code 这样长时间运行的智能体产品,之所以能够落地,提示词缓存功不可没。它让系统得以复用此前对话的计算结果,从而大幅降低延迟与成本。
那么,提示词缓存究竟是什么?它如何工作?在技术层面又该怎么实现?
在 Claude Code,整个工具链都围绕提示词缓存来构建。高缓存命中率能降低成本,让我们为订阅用户提供更宽松的速率限制。因此,我们会持续监控缓存命中率——一旦命中率过低,就会触发严重事故(SEV)警报。
以下是我们在大规模优化提示词缓存过程中总结的经验教训,其中不乏反直觉之处。
为缓存设计你的 Prompt 布局

核心原则是:静态内容在前,动态内容在后。在 Claude Code 中,布局依次为:
- 静态系统提示词 & 工具定义(全局缓存)
- CLAUDE.MD(在项目内缓存)
- 会话上下文(在会话内缓存)
- 对话消息
但这个顺序极其脆弱。我们曾多次不小心打乱它,原因包括:在静态系统提示词中混入了精确时间戳、随机打乱了工具定义的顺序、更新了工具参数(例如 AgentTool 可调用的智能体列表)等。
用消息传递更新,而非修改提示词
有时,提示词中的信息会过时——比如时间变了,或者用户修改了文件。直觉上你会想直接更新提示词,但这会让缓存失效,让用户承担高昂成本。
更好的做法是:在下一轮对话中,通过消息来传入这些更新。在 Claude Code,我们会在下一条用户消息或工具结果中附加
<system-reminder> 标签,写入最新信息(例如"今天是周三")。这样就能保留之前的缓存前缀,同时完成信息更新。别在会话中途切换模型
提示词缓存是模型专属的,这使得成本计算变得非常反直觉。
假设你与 Opus 的对话已累积了 10 万个 token,此时想问一个简单问题,切换到 Haiku 反而比让 Opus 直接回答更贵。原因在于:切换后需要为 Haiku 重新构建整个提示词缓存。
如果确实需要切换模型,最稳妥的方式是使用子智能体(subagents):让 Opus 准备一条"交接消息",由子智能体接手特定任务。这正是我们在 Claude Code 的 Explore 智能体中常用的做法——它会调用 Haiku 来完成部分工作。
切勿在会话中途增减工具
在对话过程中更换工具集,是导致提示词缓存失效最常见的原因之一。
这听起来违反直觉——你可能觉得应该只给模型提供它当前需要的工具。但由于工具定义是缓存前缀的一部分,任何增减操作都会让整段对话的缓存全部失效。
规划模式:围绕缓存来设计功能
"规划模式"(Plan Mode)是围绕缓存约束来设计功能的一个好案例。
最直觉的做法是:当用户进入规划模式时,把工具集换成只包含只读工具。但这会破坏缓存。
我们的方案是:始终在请求中保留所有工具。我们把
EnterPlanMode 和 ExitPlanMode 本身设计成工具。当用户开启规划模式时,智能体会收到一条系统消息,说明它处于规划模式,并给出相应指令:探索代码库、不要编辑文件、完成后调用 ExitPlanMode。工具定义始终不变。这还带来一个额外好处:由于
EnterPlanMode 本身是个工具,模型在遇到复杂问题时可以自主决定进入规划模式,且不会中断缓存。工具搜索:延迟加载,而非移除
同样的原则也适用于工具搜索功能。Claude Code 可以加载数十个 MCP 工具,如果每次请求都包含所有工具,成本会非常高;但在对话中途移除它们又会破坏缓存。
我们的解决方案是
defer_loading(延迟加载):不移除工具,而是发送轻量级的存根(stubs)——只包含工具名称,并标记 defer_loading: true。模型在需要时可以通过 ToolSearch 工具"发现"它们,只有被选中时才加载完整的工具定义。这样一来,缓存前缀始终稳定:相同的存根以相同的顺序出现,不会引发失效。你也可以直接通过我们的 API 使用工具搜索(tool search)来简化这一过程。
分叉上下文:压缩的那些坑
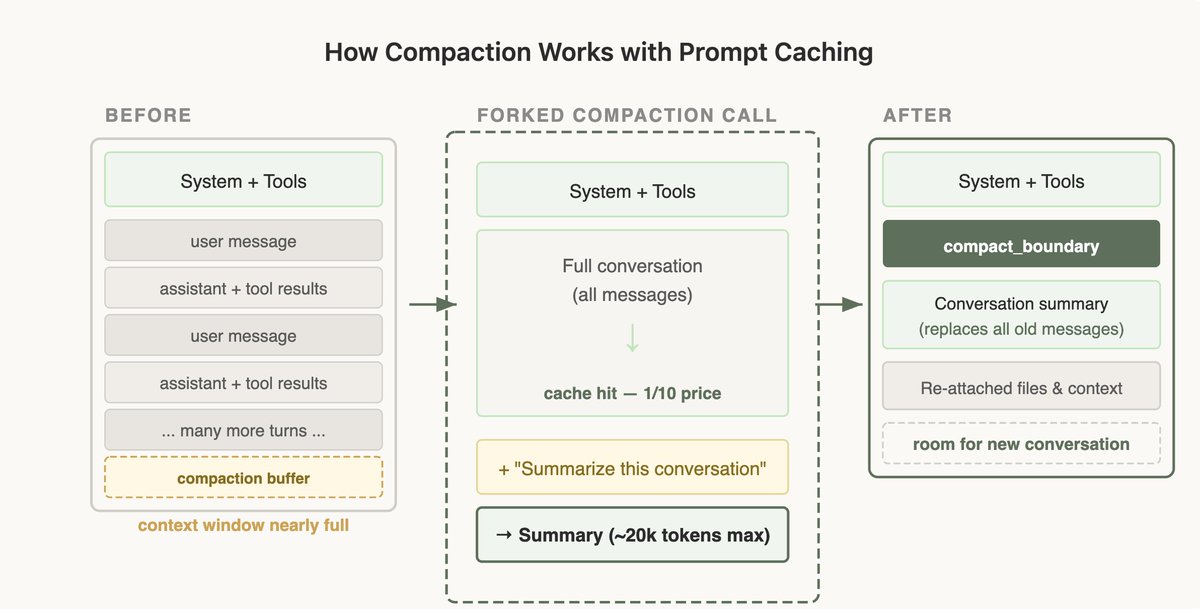
当上下文窗口用尽时,就会触发"压缩"(Compaction):系统会对此前的对话生成摘要,并以摘要为起点开启新会话。
压缩在提示词缓存方面有很多反直觉的边缘情况。
最典型的一个:执行压缩时,我们需要把完整对话发给模型来生成摘要。如果这是一个独立的 API 调用——使用不同的系统提示词、不带工具(这是最简单的实现方式)——它与主对话的缓存前缀完全不匹配,所有输入 token 都要按全价计费,用户成本会急剧上升。
解决方案:缓存安全的分叉(Cache-Safe Fork)
执行压缩时,我们会使用与原对话完全相同的系统提示词、用户上下文、系统上下文和工具定义,先放入原有的对话消息,再在末尾追加压缩指令作为新用户消息。
从 API 视角来看,这个请求与上一次请求几乎一模一样——相同的前缀、工具和历史——因此缓存前缀得以复用。真正产生费用的新 token,只有末尾的压缩指令本身。
当然,这要求我们预留"压缩缓冲区",确保上下文窗口留有足够空间来放入压缩消息和生成的摘要 token。
压缩处理虽然棘手,但好消息是:基于 Claude Code 的实战经验,我们已经将压缩(compaction)功能直接内置到 API 中,你可以在自己的应用里直接使用这些模式,无需重复踩坑。
经验总结
- 提示词缓存是前缀匹配。 前缀中任何位置的改动都会让其后的所有内容失效。请围绕这个约束来设计整个系统——只要顺序对了,大部分缓存都能自动生效。
- 用消息传递状态,而非修改系统提示词。 切换模式、更新日期等操作,应通过在对话中插入消息来完成,而不是改动提示词。
- 不要在对话中途更换工具或模型。 用工具来模拟状态转换(如规划模式),而不是替换工具集;用延迟加载代替移除工具。
- 像监控服务可用性一样监控缓存命中率。 我们将缓存中断视为事故并设置警报——命中率哪怕只下降几个百分点,对成本和延迟的影响都不容忽视。
Claude Code 从第一天起就是围绕提示词缓存来构建的。如果你也在开发智能体,建议从一开始就把缓存作为核心设计约束。