Created time
Apr 7, 2026 04:45 AM
category
library
date
Mar 31, 2026
status
Published
icon
password
slug
skills-creation-anthropic-skill-creator
type
post
likes
views
summary
如何利用Anthropic的skill-creator提升和测试智能体技能?
tags
Agent
工程实践
Claude
Skill-creator 现在可以帮你编写评估(evals)、运行基准测试,并确保你的技能在模型演进过程中持续有效。这些更新现已在 Claude.ai 和 Cowork 中上线。同时,它也作为 Claude Code 插件提供,并同步更新在我们的代码库中。
自去年 10 月发布 Agent Skills 以来,我们发现大多数创作者是领域专家,而非工程师。他们熟悉自己的工作流,但缺乏工具来判断:技能在面对新模型时是否依然有效?是否在正确时机触发?或者修改后是否真的变好了?
今天,我们宣布了 skill-creator 的增强功能,旨在帮助创作者更有信心地进行构建。我们将软件开发的严谨性(测试、基准测试、迭代改进)引入了技能创作,且无需编写任何代码。
两种技能类型
技能通常分为两类:
能力提升类(Capability uplift):这类技能帮助 Claude 完成基础模型无法做到、或无法稳定做到的任务。我们的文档创建技能就是很好的例子。它们封装了特定的技巧和模式,能产生比单纯提示词更好的效果。
偏好封装类(Encoded preference):这类技能用于记录工作流。虽然 Claude 已经能完成其中的每个环节,但技能会按照团队的特定流程进行排序。例如:根据设定标准审查 NDA 的技能,或从不同 MCP 获取数据并起草周报的技能。
这种区分很重要,因为这两类技能的测试目的不同:
- 随着模型能力的提升,能力提升类技能可能变得不再必要。评估(Evals)能告诉你这种情况何时发生。
- 偏好封装类技能更持久,但其价值取决于对实际工作流的还原度。评估可以验证这种还原度。
无论哪种情况,测试都能让一个“看起来有用”的技能变成一个“确定有用”的技能。
使用评估(Evals)测试并改进技能
Skill-creator 现在可以帮你编写评估(evals)。评估是用来检查 Claude 是否按预期响应提示词的测试。如果你写过软件测试,会觉得这很亲切:定义一些测试提示词(必要时附带文件),描述理想的输出结果,skill-creator 就会告诉你该技能是否达标。
以我们的 PDF 技能为例,它以前很难处理不可填写的表单。Claude 必须在没有预设字段引导的情况下,将文本放在精确的坐标上。评估定位了这一失败点,随后我们发布了修复方案,将定位锚定在提取的文本坐标上。
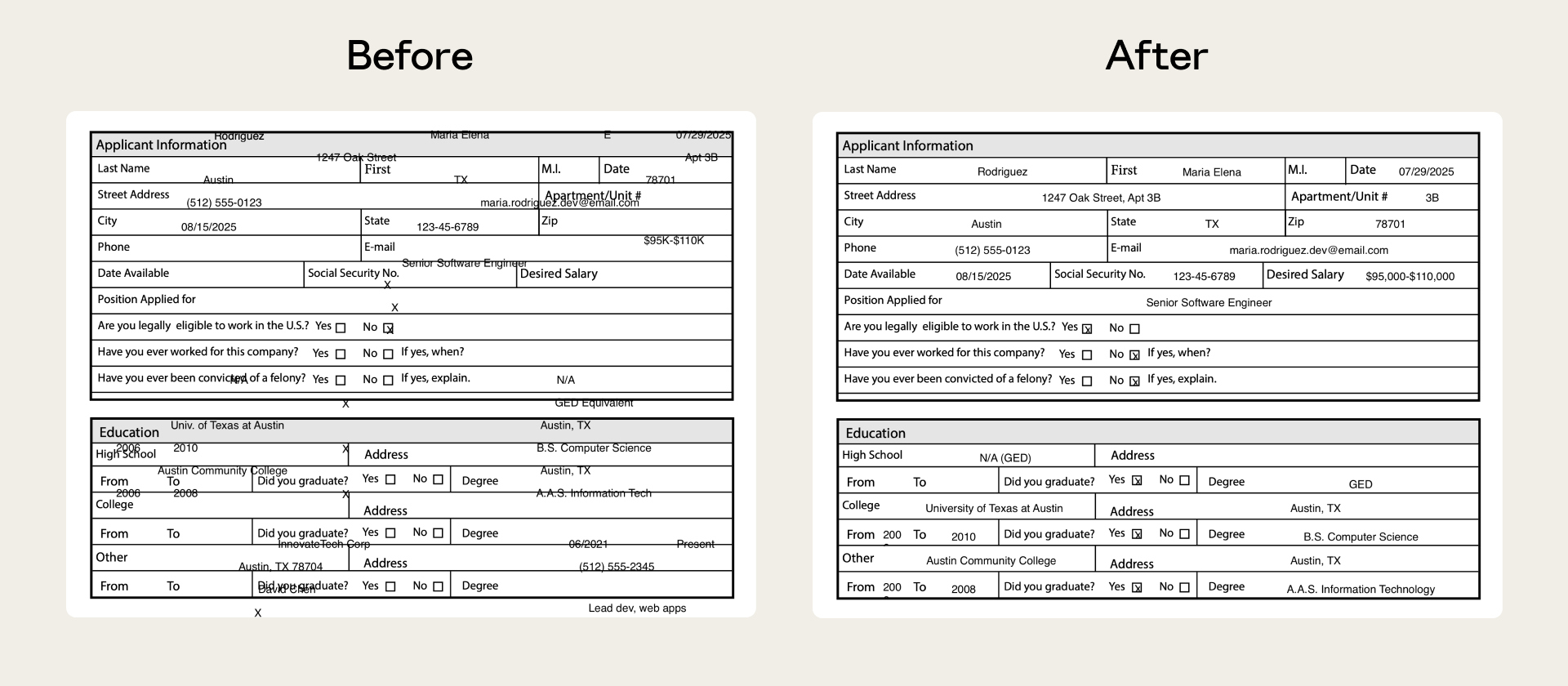
评估有很多用途,其中两个最重要的用途是:捕捉质量退化和了解模型进展。
第一,捕捉质量退化。随着模型及其周边基础设施的演进,上个月还好用的技能,今天可能表现不同。针对新模型运行评估,可以在问题影响团队工作之前,提前发现变化信号。
第二,了解模型能力是否已超越技能。这主要适用于能力提升类技能。如果基础模型在不加载技能的情况下也能通过评估,说明该技能的技巧可能已被整合到模型的默认行为中。技能没坏,只是不再需要了。
我们还添加了基准测试模式(benchmark mode),可以使用你的评估进行标准化测评。你可以在模型更新后或迭代技能时运行它。它会追踪评估通过率、耗时和 Token 使用情况。
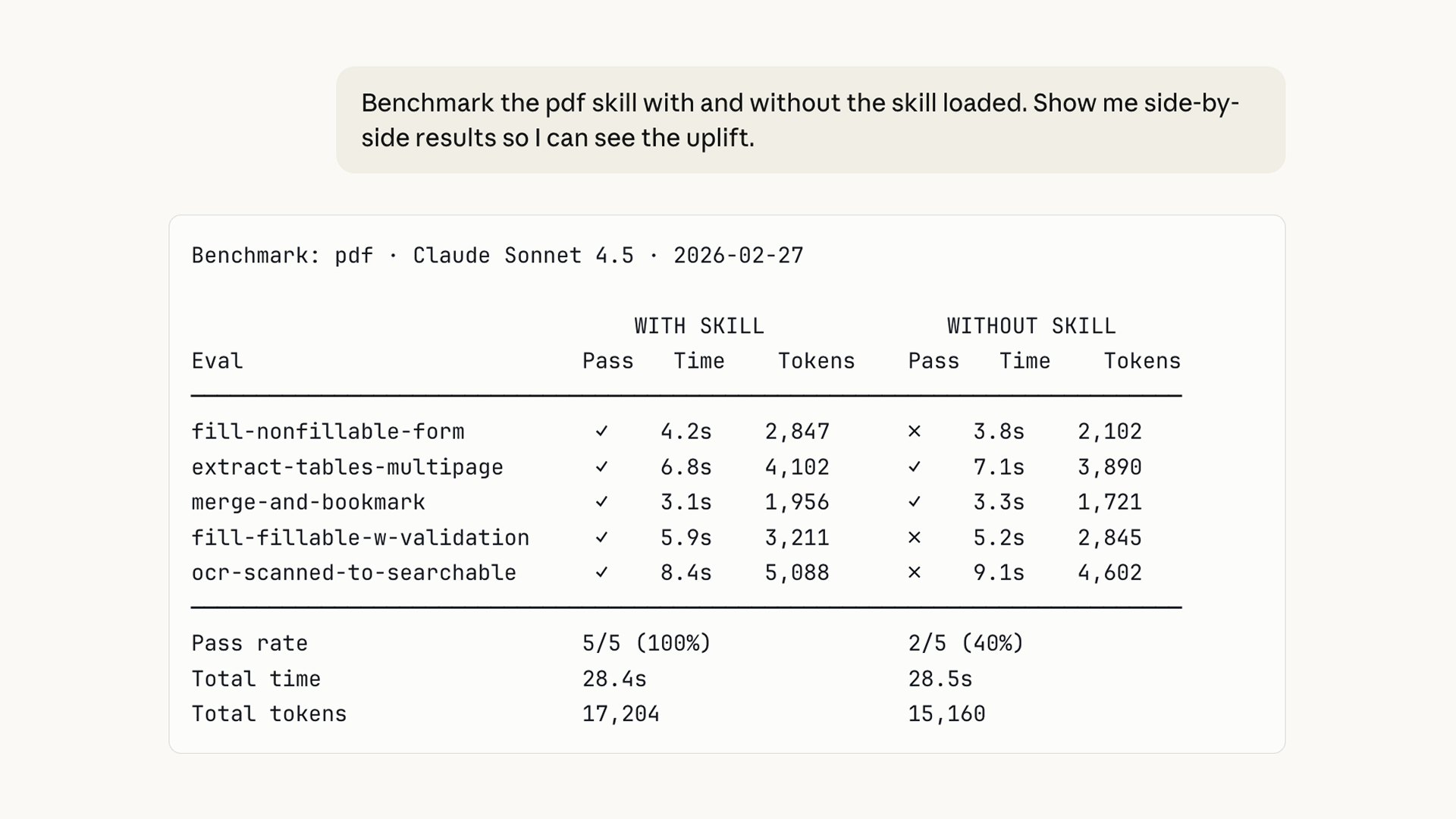
你的评估和结果由你自己掌握。可以将它们存储在本地,集成到仪表板,或接入 CI 系统。
多智能体支持:更快、更一致的评估
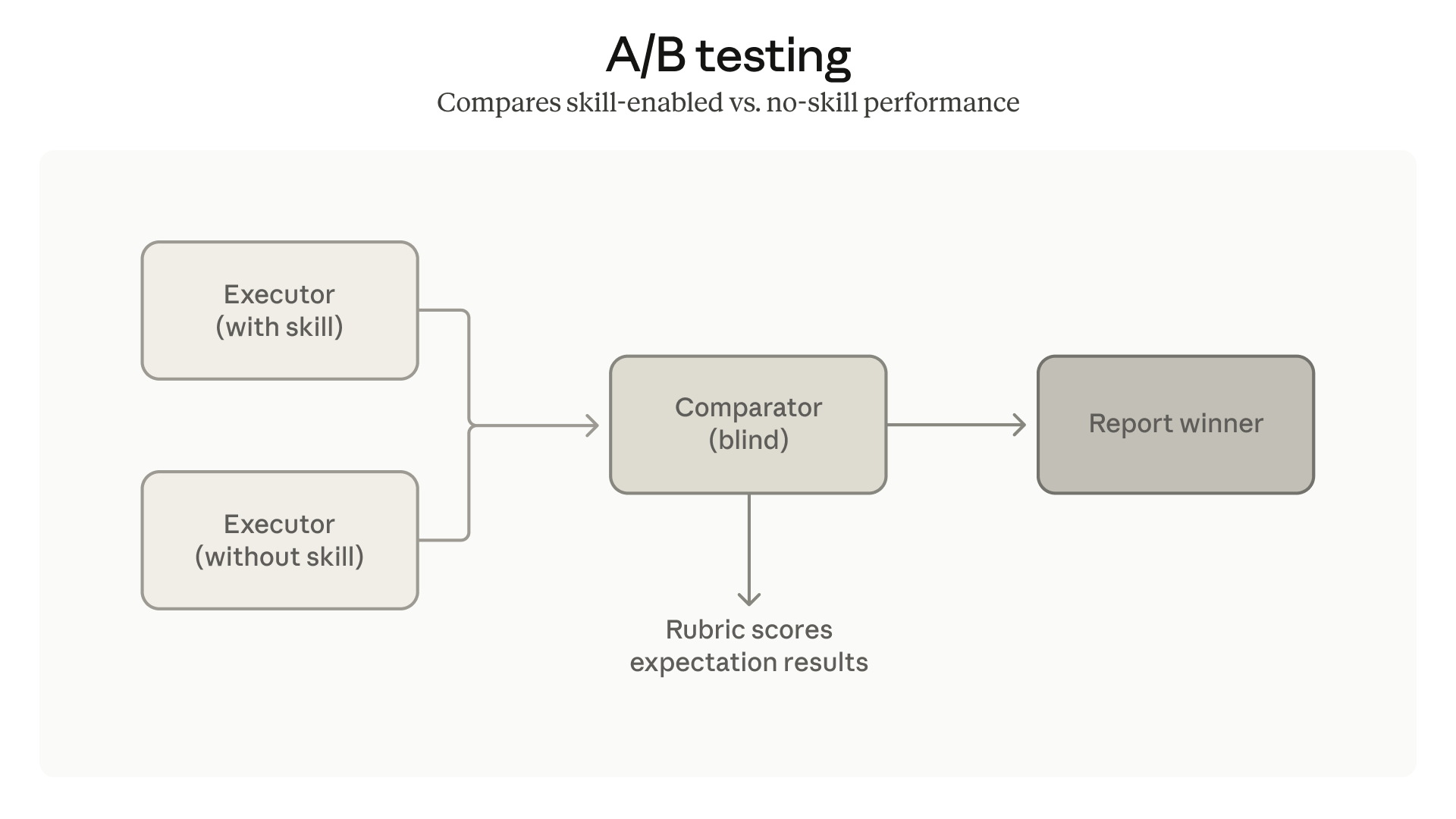
顺序运行评估可能很慢,且累积的上下文可能会在不同测试间产生干扰。Skill-creator 现在支持多智能体(multi-agent)并行运行评估。每个智能体都在干净的上下文中运行,拥有独立的 Token 和计时指标。结果更快,且无交叉污染。
我们还添加了比较智能体(comparator agents)用于 A/B 测试:比较两个技能版本,或比较“有技能”与“无技能”。它们在不知道版本归属的情况下对输出进行评判,从而帮你判断修改是否真的有效。
让技能在正确的时间触发
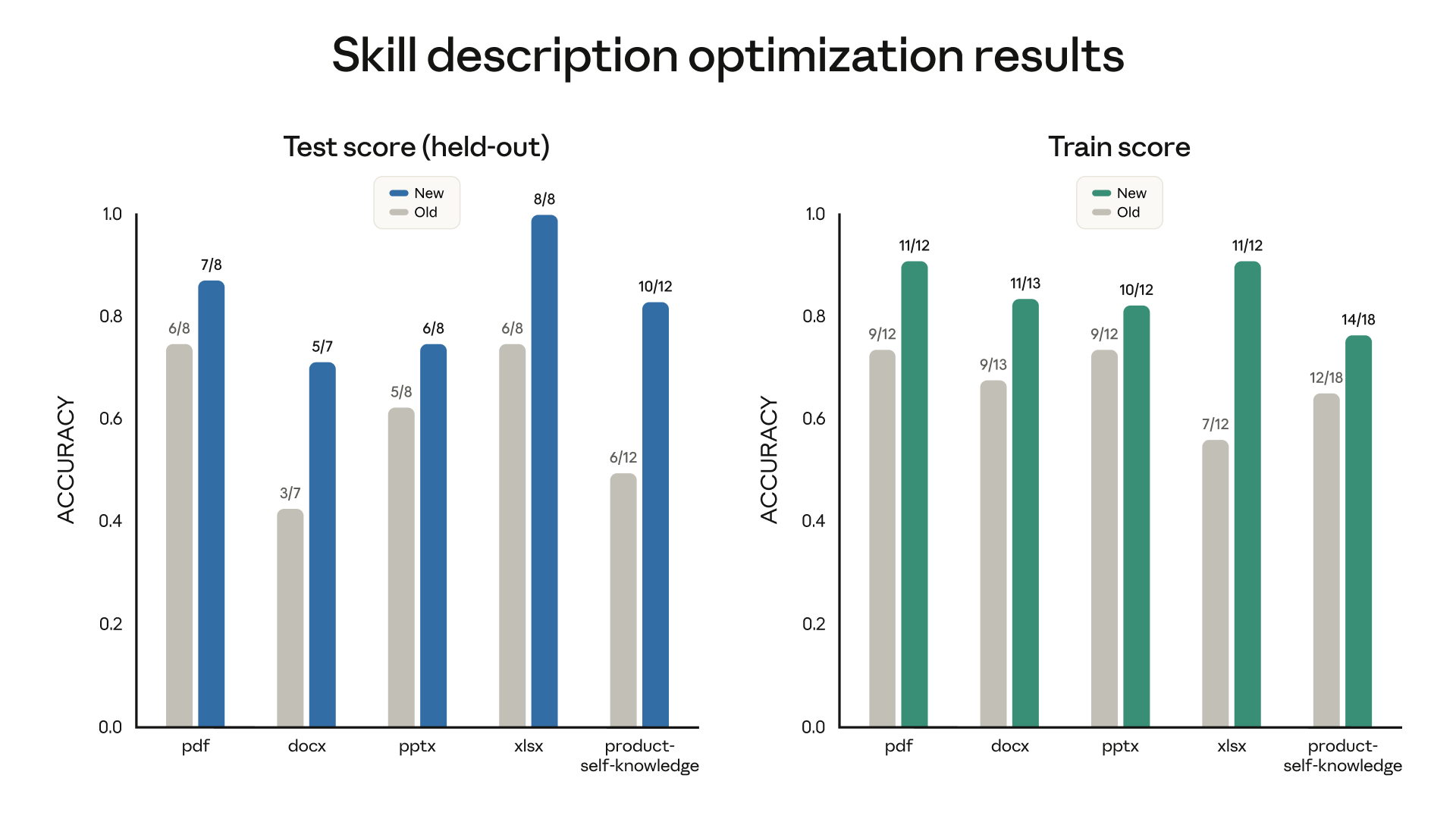
评估衡量的是输出质量,但前提是技能要在该触发时触发。随着技能数量增加,描述的精准度变得至关重要:描述太宽泛会导致误触发,太窄则永远不会启动。Skill-creator 现在能帮你优化描述,使触发更可靠。它会根据示例提示词分析你当前的描述,并建议修改方案,以减少误报和漏报。
我们在文档创建技能上运行了该功能,发现 6 个公开技能中有 5 个的触发准确率得到了提升。
展望未来
随着模型能力的提升,“技能”与“规范”之间的界限可能会变得模糊。今天,一个 SKILL.md 文件本质上是一个执行计划,通过详细指令告诉 Claude 如何(how)做某事。未来,可能只需一段关于技能要做什么(what)的自然语言描述就足够了,剩下的交给模型去解决。
我们今天发布的评估框架就是朝着这个方向迈出的一步。评估已经描述了“要做什么”。最终,这种描述本身可能就是技能。
开始使用
所有 skill-creator 的更新现已在 Claude.ai 和 Cowork 上线。只需让 Claude 使用 skill-creator 即可开始。