Created time
Feb 19, 2026 02:58 PM
category
library
date
Oct 9, 2025
status
Published
icon
password
slug
b2b-generative-ai-less-is-more
type
post
likes
views
summary
B2B 生成式 AI 的未来在于信息的“合成”,而非单纯的内容“生成”。
tags
AI+商业
A16z
这是一篇来自 a16z 的深度洞察,虽然是23年发布的文章,但文章中很多观点,直到今天回看仍然非常准确:
- B2B与B2C的AI在目标(效率/质量 vs 娱乐/分享)、要求(准确性、可靠性)等方面存在显著差异
- 早期的AI更偏向"发散"即如何产生新内容,而ToB的AI更需要"收敛",即如何更精简、更聚焦、更正确。
- ToB市场中AI的竞争中获胜的关键,并非谁能构建 AI 合成能力;而是谁能掌控工作流。
以下为AI翻译整理。
过去几年,大模型(LLM)彻底破圈。虽然技术进步神速,但在 B2B(企业级)应用领域,我们认为这仅仅是“第一波”浪潮。
随着企业开始深挖应用场景并构建产品护城河,AI 的玩法正在发生根本性转变:从“第一波”的漫无目的,转向“第二波”的精准聚焦。
核心逻辑在于:到目前为止,生成式 AI 都在做“信息发散”(Divergence)——根据指令生成海量新内容。但在第二波浪潮中,我们认为 AI 将转向“信息收敛”(Convergence)。
简单来说,未来的 AI 不会给你更多内容,而是通过合成(Synthesis)现有信息,给你更少、更精炼的结论。我们称之为 SynthAI(合成式 AI)。
最终,B2B 领域的胜负手不在于谁的 AI 技术更酷炫,而在于谁能利用这些能力,真正占领(甚至重塑)企业最有价值的工作流。
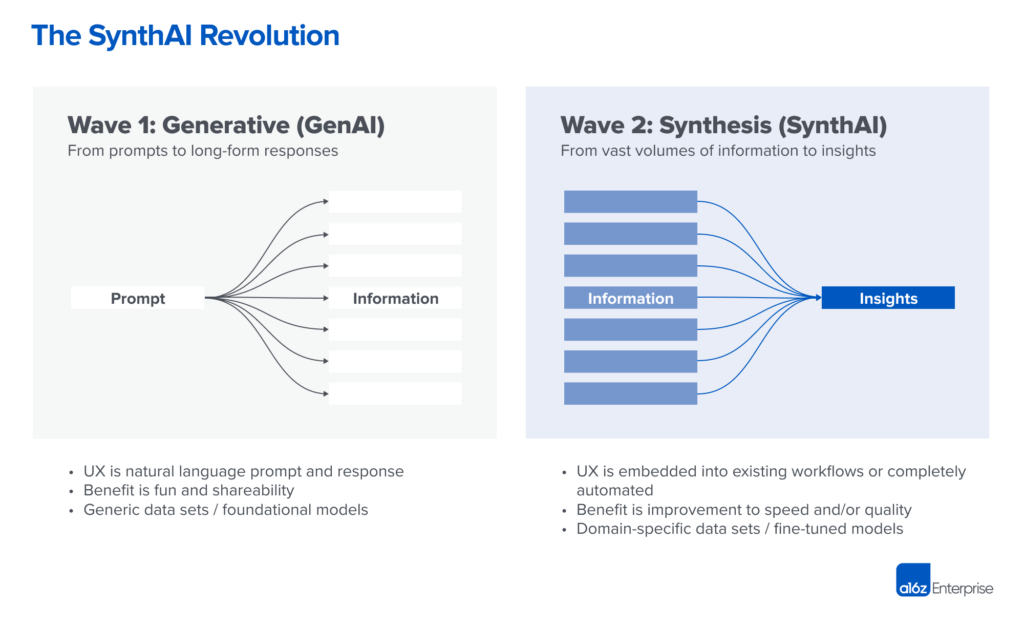
第一波:从“消费端”到“企业端”的生搬硬套
要理解现状,得先看清 B2C 和 B2B 的本质区别。
在 B2C(消费者) 世界,我们用 AI 主要是为了“好玩”或“分享”。质量和准确性不是第一优先级。AI 画张图、写首歌,你在 Discord 里显摆一下就完了。人类天生有一种错觉:觉得“多”就等于“生产力高”,所以我们迷恋自动化生成。ChatGPT 的爆火就是典型:哪怕它一本正经胡说八道,只要它写得够长、够像样,大家就觉得很厉害。
但在 B2B(企业) 场景,逻辑变了。这里只有冷冰冰的成本效益评估:时间 vs 质量。你要么用同样的时间做出更好的质量,要么用更短的时间做出同样的质量。
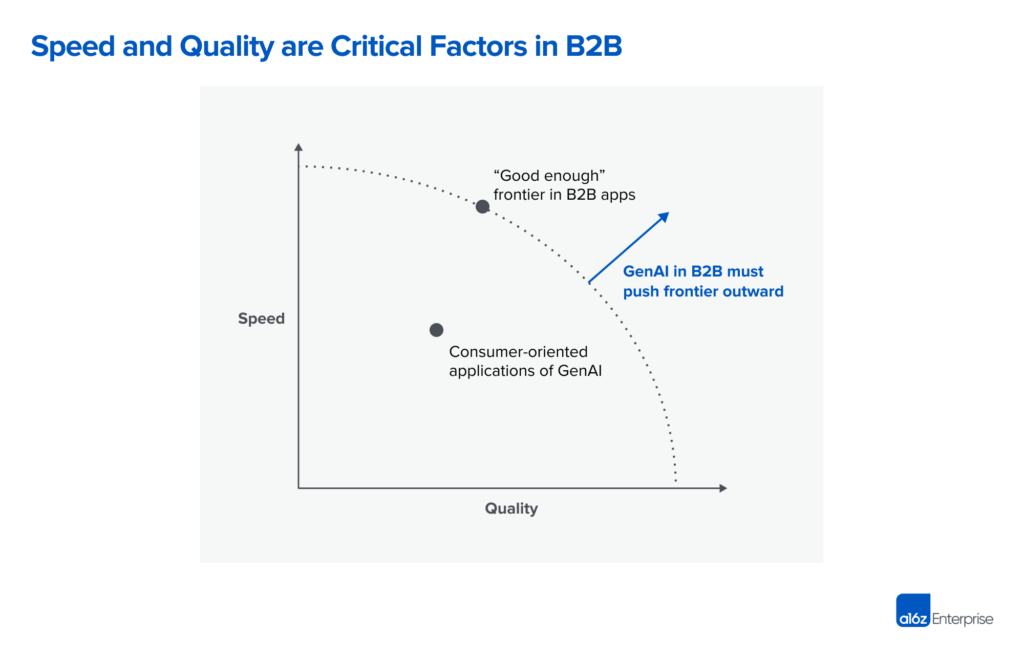
在职场,质量就是生命线。目前的 AI 只能应付一些重复性强、容错率高的“低端局”,比如写个广告文案或产品描述。但一旦涉及到需要观点、论证或决策的“高端局”,AI 就拉胯了——它看起来很自信,实则漏洞百出。
比如写销售邮件。AI 写封通用的垃圾邮件很快,但要写出一封能让客户回复、能促成签单的高质量邮件,销售还是得自己调研、自己判断。
结论是:第一波 AI 在头脑风暴和初稿阶段很有用,但越是需要创意和专业深度的地方,就越离不开人的“微操”。
为什么我们有时宁愿“自己动手”?
如果用 AI 写篇深度博客,你需要写极其精准的提示词(Prompt)。这意味着在 AI 动笔前,你脑子里必须已经有了完整的逻辑。然后你还得反复调优、修改、甚至重写。
最极端的例子是法律文件。AI 能写草案,但前提是律师得把所有条款喂给它。AI 没法替你谈判,它只是个打字员。最后,律师还是得逐字逐句审核。
这就是为什么 B2B 场景下的 AI 效率陷阱:如果为了用 AI 而增加的步骤(写 Prompt + 纠错),比直接上手写还费劲,那知识工作者肯定会选择“自己来”。
第二波:为了决策而“收敛”信息
进入第二波,AI 的重心将从“生成”转向“合成”。
在知识型工作中,最值钱的是决策。老板付钱是让你在信息不透明的情况下拍板,而不是看你写了多少字。代码行数不代表生产力,PPT 越长不代表洞察越深。
Hex 的 CEO Barry McCardel 说得好:“AI 是来增强人类的,不是来取代人类的。理解世界和做决策,必须有人在场。”
那么 AI 如何辅助决策?LLM 必须进化为 SynthAI。
最直观的应用是:处理人类根本读不完的海量信息。我们设想的未来 UI 可能和 ChatGPT 完全相反:不是“短指令生成长文章”,而是“从海量数据中反向推导出那条最关键的指令/结论”。
比如像 Mem 这样的 AI 知识库,它能自动关联公司里所有的会议纪要,在你开始新项目时,直接告诉你:“嘿,之前某某做过类似的,你可以参考他的结论。”这能帮你省掉几天的调研时间。
在销售场景下,SynthAI 不是帮你写 100 封邮件,而是分析新闻、财报、人才流动,然后提醒你:“这个客户现在最有购买意向,建议你提这两个重点。”
为了实现这种高质量的合成,行业将从“通用大模型”转向“多模型架构”——利用针对特定行业、特定数据微调过的私有模型。这才是企业真正的护城河。
SynthAI 的落地场景
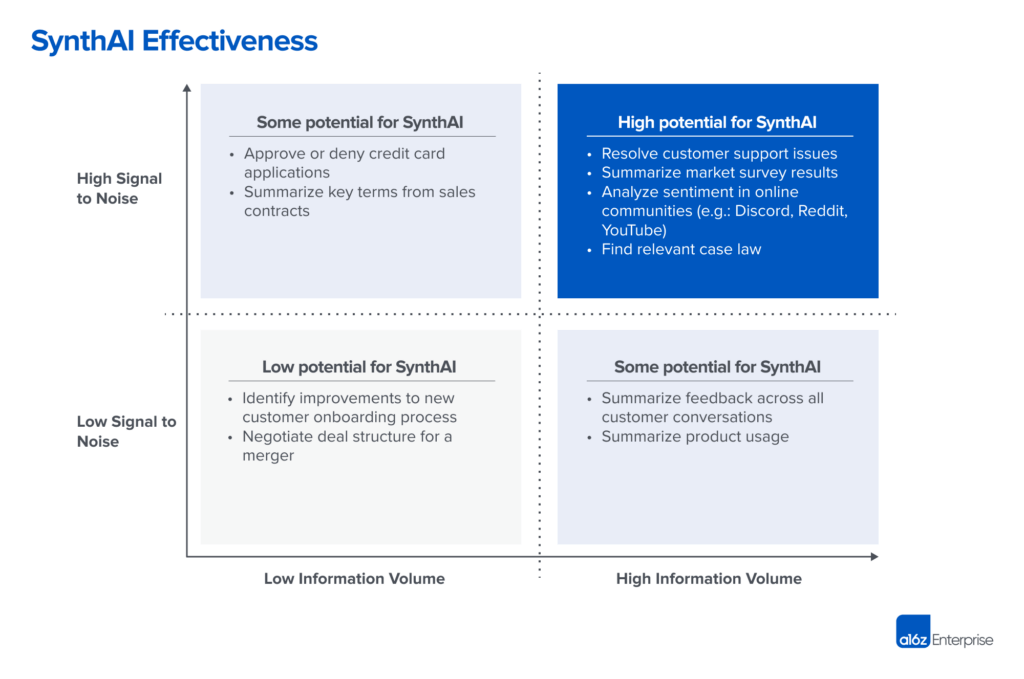
我们认为,最适合 SynthAI 的场景具备两个特征:
- 信息量巨大:人看不过来。
- 信噪比高:虽然数据多,但核心规律是清晰的。
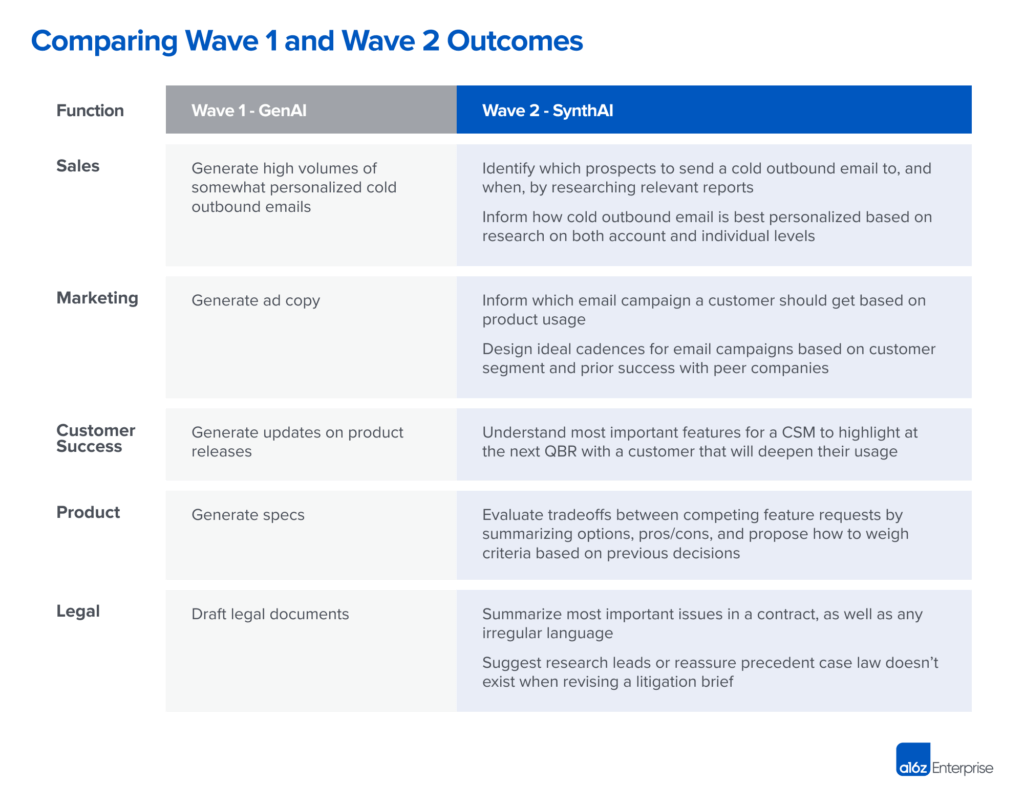
下表对比了第一波(生成)与第二波(合成)的差异:
终极决战:谁能吃掉“工作流”?
现在,老牌软件巨头(System of Record)和 AI 原生创业公司正在赛跑。
大家要抢的奖杯不是“谁的 AI 总结得好”,而是**“谁能占领工作流”**。老牌厂商想用 AI 巩固地盘,创业公司想用 AI 作为楔子,重塑整个办公流程。
比如做产品反馈的 Sprig。以前他们用 AI 总结用户反馈,还需要人工审核一遍才敢给客户看。现在,LLM 让他们有信心直接实时输出结论,甚至能让用户针对某个结论进行“追问”。
再看销售领域,ZoomInfo 已经把 GPT 整合进了平台。与此同时,无数 AI 原生创业公司正试图从零开始自动化整个销售流程。
结语
AI 改变工作的戏码才刚刚开场。B2B 领域的生成式 AI 必须跳出“制造内容”的怪圈,进化为“合成信息”的利器。
在这场关于“工作流”的权力游戏中,谁能让用户决策得更快、更准,谁才是最后的赢家。这场“少即是多”的进化,值得我们每个人关注。