Created time
Feb 24, 2026 09:45 AM
category
library
date
Feb 24, 2026
status
Published
icon
password
slug
measuring-agent-autonomy
type
post
likes
views
summary
如何有效监管AI智能体的自主性边界?
tags
Claude
技术解读
原文:Measuring AI agent autonomy in practice,Anthropic,2026年2月18日。以下基于论文博客原文进行翻译,有精简。
为什么要研究这个问题?
AI智能体已经在用了——从筛选邮件到网络间谍,应用场景的风险跨度极大。
但现实是:我们对人们究竟如何使用智能体,几乎一无所知。
为了填补这个空白,研究团队在隐私保护前提下,分析了Claude Code平台与公开API上的数百万次人机交互数据,重点围绕四个问题:
- 人类给了智能体多大的自主空间?
- 随着使用经验积累,这个空间如何变化?
- 智能体主要活跃在哪些领域?
- 它执行的操作,有多少存在风险?
核心发现
1|自主运行时间在快速增长
Claude Code的"无干预运行时长"在三个月内几乎翻倍——从不足25分钟,延长至超过45分钟。
关键点:这一增长跨越了不同模型版本,说明并非单纯因为模型变强。现有模型的自主能力,已远超人们实际使用的上限。
2|老用户更放手,但也更频繁打断
随着用户熟悉Claude Code,他们会逐渐从"逐步审批"切换到"全程自动"——新用户全自动模式占比约20%,老用户则超过40%。
但与此同时,老用户中断智能体的频率也更高。放手更多,干预也更精准。
3|智能体自我暂停,比人类中断更频繁
智能体不只是被动执行。在最复杂的任务中,Claude Code主动暂停并询问确认的频率,是用户主动中断的两倍以上。
这说明:智能体的自我检查机制,本身就是监督体系的重要组成部分。
4|高风险领域有渗透,但尚未规模化
当前公共API中,绝大多数智能体操作风险低、可逆。软件工程占智能体活动的近50%;医疗、金融、网络安全领域已有应用苗头,但规模仍小。
研究的核心结论
有效监管智能体,需要两样新东西:部署后的实时监测基础设施,以及新型人机协作范式——让人与AI共同管理自主权与风险边界。
研究真实环境中的智能体:
本研究的起点定义:
智能体 = 配备执行工具的AI系统,工具包括:运行代码、调用外部API、向其他智能体发消息。
这是一个可操作、边界清晰的定义——也是后续所有分析的基础。
三大挑战与两条路径
为什么难做?
实证研究面临三道门槛:
- 定义不统一 — 学界对"智能体"尚无共识
- 技术迭代太快 — 去年的顶级智能体只能单线程对话,今天已有能自主运行数小时的多智能体系统
- 视野天然受限 — 作为模型供应商,我们无法把散落的API请求可靠地拼接成完整的"会话"
我们怎么做?
第一步:锁定可操作的定义。
智能体 = 配备执行工具的AI系统,工具包括:运行代码、调用外部API、向其他智能体发消息。定义清晰,研究才有地基。
第二步:构建"广度 + 深度"双数据源。
数据源 | 优势 | 局限 |
公共API | 覆盖数千客户、横向广 | 只能分析单次工具调用,无法还原完整行为链 |
Claude Code | 自有产品、可追踪完整会话 | 仅一款产品,多样性有限 |
两者结合,在隐私保护前提下互补——单一数据源回答不了的问题,双源整合能给出答案。
Claude Code:自主运行时长在增长
智能体能跑多久不被人打断?
在Claude Code中,我们逐轮追踪每次"启动→停止"的时间间隔。停止原因包括:任务完成、主动提问、或用户中断。
这个指标并不完美
"回合时长"受多重因素交织影响:
- 模型更强 → 完成同样任务更快 → 时长缩短
- 子智能体并行处理 → 时长缩短
- 用户尝试更复杂任务 → 时长延长
- 用户群体持续扩大且快速变化
我们无法将这些变量逐一剥离。最终测量值,是模型效率、任务难度、用户习惯三者的综合体现。
绝大多数交互,依然短平快
中位数交互时长约45秒,过去几个月几乎纹丝不动(40–55秒区间)。99百分位以下的指标,同样高度稳定。
这并不意外。Claude Code用户群在快速扩张,新人比例高——他们经验尚浅,倾向于给Claude更小的自主空间(下一节详述)。大量短交互拉平了整体数据,中位数自然稳定。
真正的信号藏在尾部
尾部数据,才是理解自主能力演进的窗口。
最长的那些交互,代表了Claude Code最复杂、最具挑战性的使用场景——也预示着智能体自主能力的未来方向。
数字说话:2025年10月至2026年1月,第99.9百分位交互时长几乎翻倍 —— 从不足25分钟,延长至超过45分钟(见图1)。
这意味着:在用户群整体变化不大、模型迭代有限的三个月内,顶端用户已经愿意让Claude独立运行更久、承担更复杂的任务。自主边界,正在被悄悄推远。
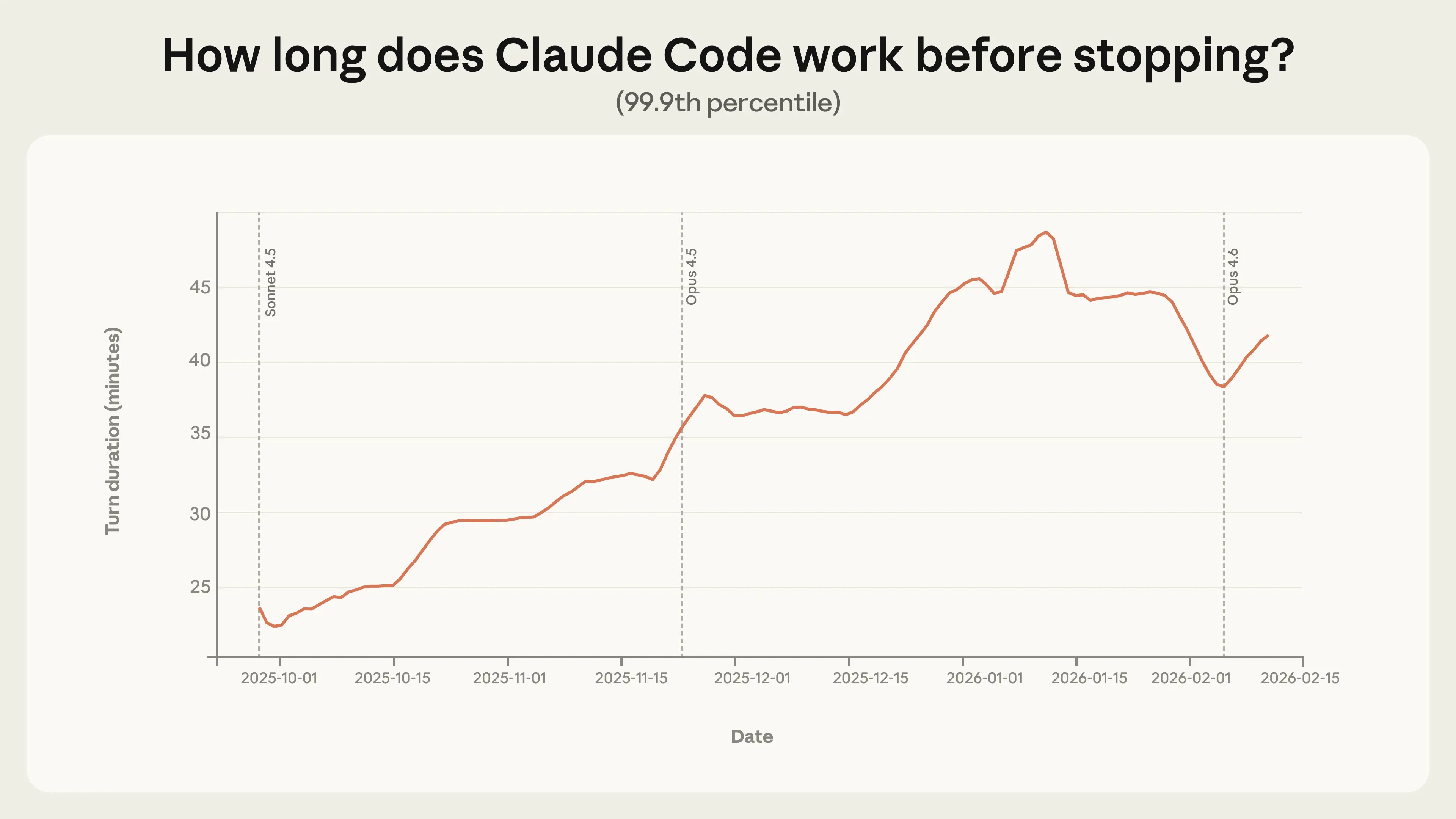
图1:转场时长的趋势与解读
互动式 Claude Code 会话的 99.9 百分位转场时长(7天滚动均值)从 9 月下旬的不足 25 分钟,持续攀升至 1 月初的 45 分钟以上。
增长为何平稳,而非跳跃式?
这一趋势跨越多个模型版本,未见明显跃升。若自主性纯粹由模型能力驱动,每次版本迭代都应产生突变——但事实并非如此。更可能的解释是多重因素叠加:资深用户逐步建立信任、任务复杂度持续提升、产品本身不断优化。
1 月中旬后,极端时长为何回落?
初步假设有两点:
- 用户规模翻倍(1月至2月中旬),更多元的会话群体重塑了分布
- 假期结束后,项目类型从兴趣驱动转向明确的工作任务
实际情况很可能是上述因素与其他未知变量的共同作用。
内部数据:能力与自主性双双提升
Anthropic 对内部 Claude Code 使用情况的分析显示:8 月至 12 月间,挑战性任务的成功率翻倍,人均干预次数从 5.4 次降至 3.3 次。
结论:更少干预,更好结果。 这两项指标共同指向同一个落差——模型的实际处理能力,远超当前实践中所赋予的自主空间。
与外部评估对比:数字不能直接比较
METR 的《AI 完成长任务能力测评》显示,Claude Opus 4.5 以 50% 成功率完成的任务,人类需耗时约 5 小时。而 Claude Code 的 99.9 百分位轮转时长约为 42 分钟,中位数更短。
但两者不可直接类比:
维度 | METR 评估 | 实测数据 |
环境 | 理想化、无人类交互 | 真实场景,含反馈与中断 |
衡量对象 | 任务难度(人类耗时) | 模型实际运行时长 |
单看任何一方都不完整。两者结合的结论是:实践中给予模型的操作自由度,仍滞后于其真实能力。
资深用户:更自动,也更主动干预
随着使用经验积累,用户会逐步放权(图2):
- 新手用户(<50次会话):约 20% 的会话启用全自动批准
- 资深用户(750次会话):比例升至 40% 以上
这一变化是渐进的,反映信任在积累。部分原因也在于产品默认要求手动批准——熟悉工具后,用户会主动调整配置,匹配自己对自主性的更高预期。
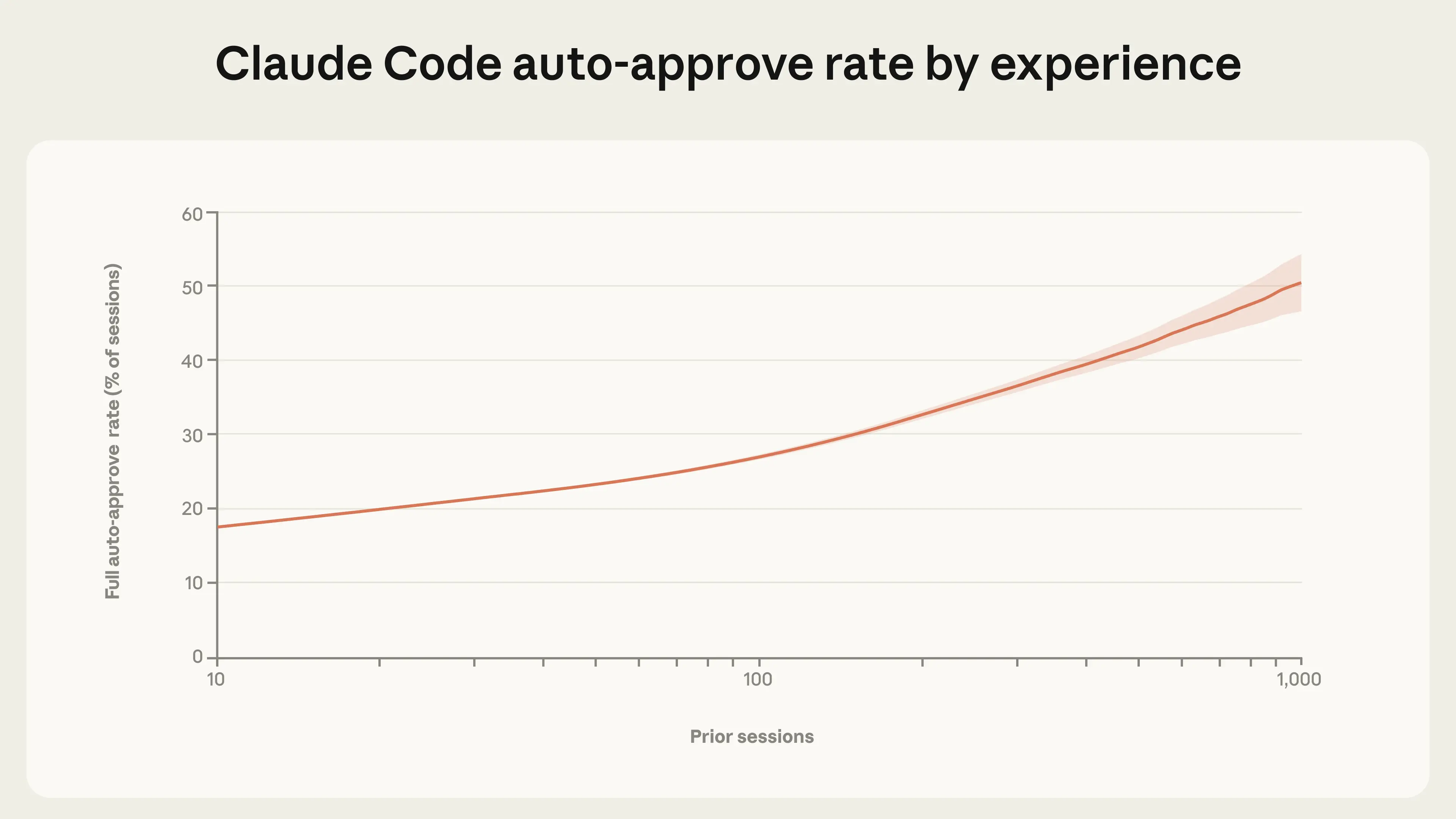
图2:自动批准率随经验线性增长
图2 按账户使用时长划分的自动批准率。数据来源:2025年9月19日后注册用户的全部交互式 Claude Code 使用记录。曲线采用 LOWESS 平滑处理(带宽 0.15),x 轴为对数刻度。
趋势明确:用户经验越丰富,越倾向于让 Claude 在无需逐条审批的情况下自主运行。
中断,是另一种监督方式
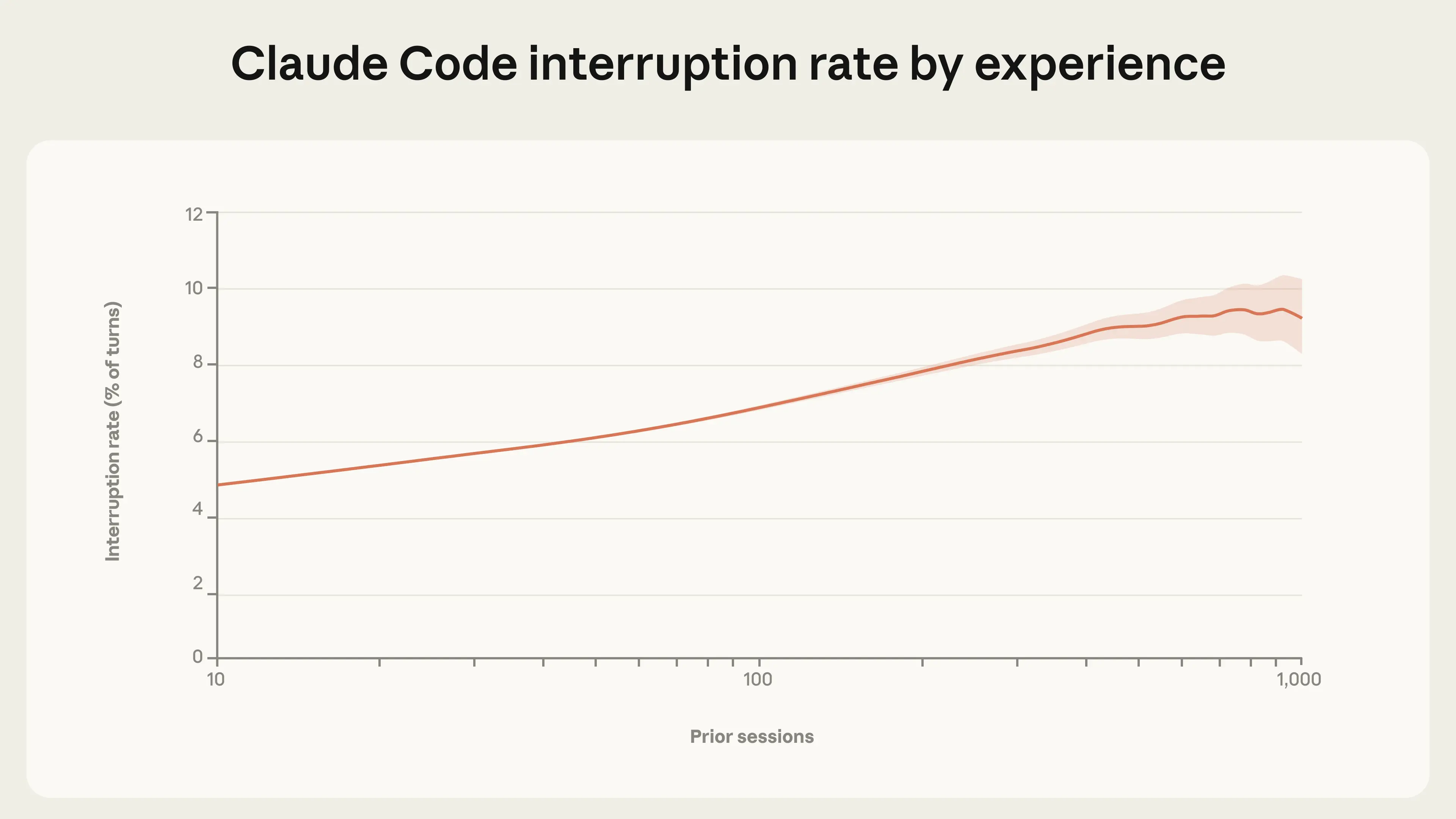
审批并非唯一的人工监督手段。用户还可以在 Claude 运行过程中随时中断,并给出反馈。
数据显示,中断率同样随经验增长而上升:
用户阶段 | 会话次数 | 中断率 |
新手 | ~10 次 | 5% |
资深 | 高经验段 | ~9% |
(见图3)
怎么理解这个现象?
两种监督行为方向相反却同步增长——自动批准率上升(放权),中断率也上升(主动干预)。这并不矛盾:资深用户并非盲目信任,而是建立了更精细的判断机制——常规操作放手,异常情况即时介入。 这是一种更成熟的人机协作模式,而非简单的"越来越懒"。
公共 API 的同一规律:复杂任务≠更多干预
在公共 API 上,同样观察到反直觉的现象:
任务复杂度 | 示例 | 人工干预率 |
低(单行修改) | 编辑一行代码 | 87% |
高(自主完成) | 发现零日漏洞、编写编译器 | 67% |
为什么复杂任务反而干预更少?
两个原因:
- 结构性限制:步骤越多,逐级审批越不现实,用户自然倾向于整体放权
- 用户构成差异:复杂任务更多来自资深用户,而资深用户本就更习惯给予自主权
虽然无法直接量化 API 用户的经验程度,但这与 Claude Code 的观察高度吻合。
核心结论:监督 ≠ 逐项审批
综合以上数据,得出一个清晰结论:
资深用户并没有"放弃监督",而是在升级监督方式。
中断率与自动批准率同步上升,恰恰说明存在主动监控机制——不是减少了参与,而是把介入的时机留给了真正重要的节点。有效的监督,是在关键时刻具备干预能力,而非对每一步操作都审批放行。
Claude 自己也会"踩刹车"
人类不是唯一的调节者。Claude 本身也是主动参与者。
当遇到不确定的情况时,Claude Code 会主动暂停并寻求澄清。数据显示:
- 随着任务复杂度上升,Claude 提出澄清请求的频率显著增加
- 且高于人类主动中断的频率(见图4)
这意味着,人机协作中的"刹车机制"是双向的——不只是人类在监督 Claude,Claude 也在主动识别边界、请求确认。
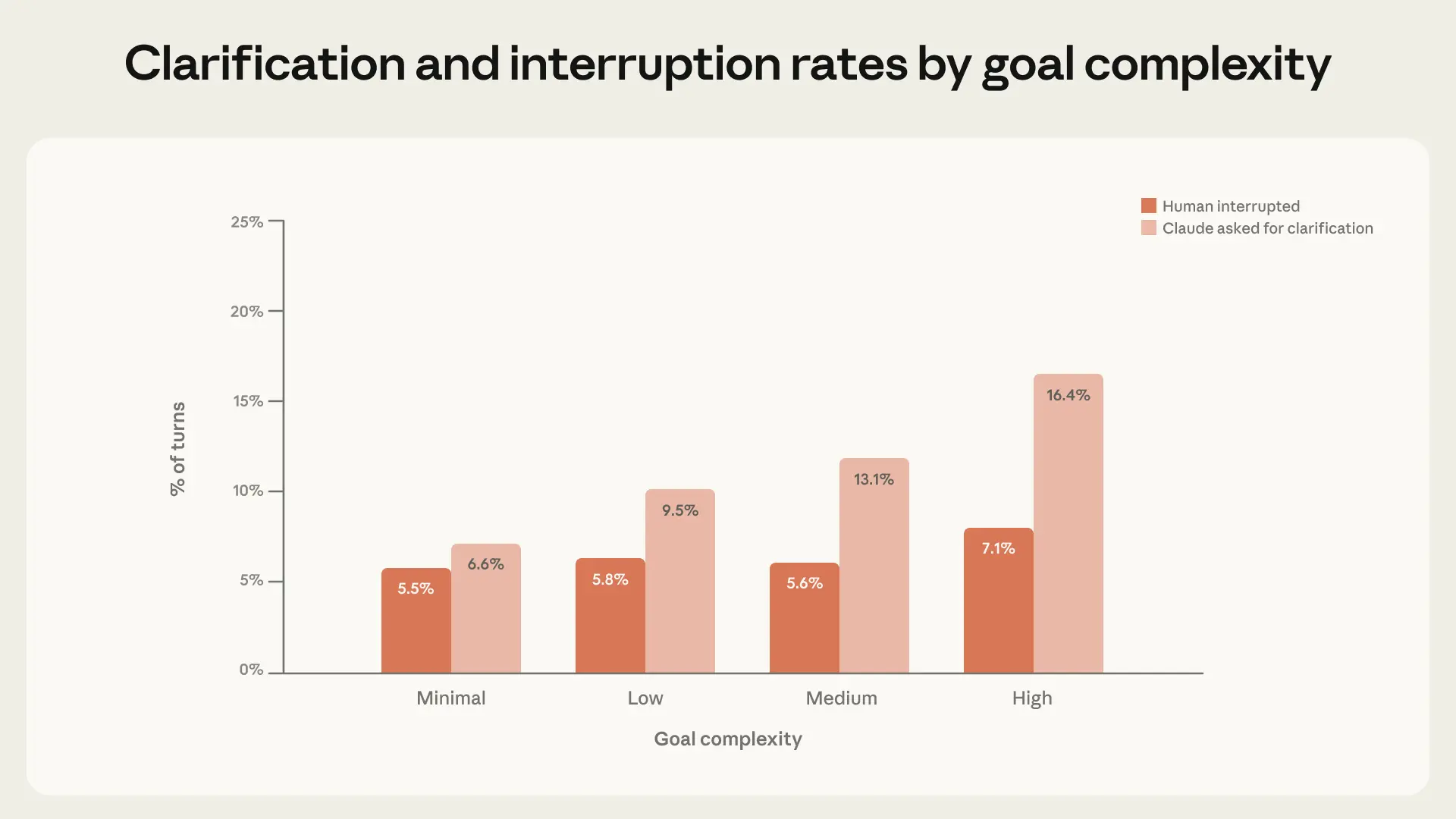
解读图4:双向刹车的数据证据
图4 不同任务复杂度下,Claude 澄清请求频率与人类中断频率的对比。数据源自 50 万次交互式 Claude Code 会话,所有类别 95% 置信区间均低于 0.9%。
两条关键发现:
- 任务越复杂,Claude 主动请求澄清的频率越高
- Claude 的暂停频率增速快于人类的主动中断频率
不要过度解读: Claude 未必总在正确时机停下,也可能提出多余的问题,且行为本身会受产品设置(如计划模式)影响。但方向是清晰的——任务越难,Claude 越倾向于主动踩刹车,而不是等人类叫停。
表1:Claude 为什么停下来?
表1 Claude Code 主动停止与人类中断的常见原因分类。基于 50 万次人类中断 + 50 万次完成交互的会话样本,由 Claude 自行判定,部分聚类略作编辑以提升可读性。
这张表传递的核心信号:主动停止,是一种监督机制。
训练模型识别自身不确定性,与权限系统、人工审批等外部安全机制互为补充。Anthropic 的做法是:在 Claude 遇到模糊任务时,鼓励它主动提问——并希望其他模型开发者也采取同样的训练策略。
智能体正进入高风险领域,但规模尚小
几个关键问题浮出水面:
- 智能体现在被用来做什么?
- 这些部署有多危险?
- 自主性越高,风险越大吗?
量化方法:风险 × 自主性双维评分
Anthropic 使用 Claude 对公共 API 中的单次工具调用进行打分,两个维度各 1–10 分:
维度 | 低分(1分) | 高分(10分) |
风险 | 失误无后果 | 可能造成重大危害 |
自主性 | 严格遵循人类指令 | 完全独立运作 |
相似操作归入同一簇组,计算各组平均分,形成可比较的分布图。
表2:高风险 / 高自主性操作的真实样貌
表2 平均风险值或自主性值偏高的操作聚类。基于公共 API 中 998,481 次随机工具调用。
重要前提: 由于对下游代理的可见性有限,部分高风险操作可能是模拟的——金融交易未必真实执行,"数据外泄"很可能是评估测试。但即便实际占比较低,一次真实的高风险失误,代价可能极为严重。
现状:大多数操作有护栏,但不可逆操作依然存在
指标 | 数据 |
具备至少一种安全防护机制的工具调用 | 80% |
存在某种人工干预环节的操作 | 73% |
具有不可逆性的操作(如发送邮件) | 0.8% |
图5 则将所有聚类的风险与自主性联合分布可视化——每个点对应一组操作,位置由两个维度的平均分决定,整体呈现出当前智能体部署的真实风险格局。
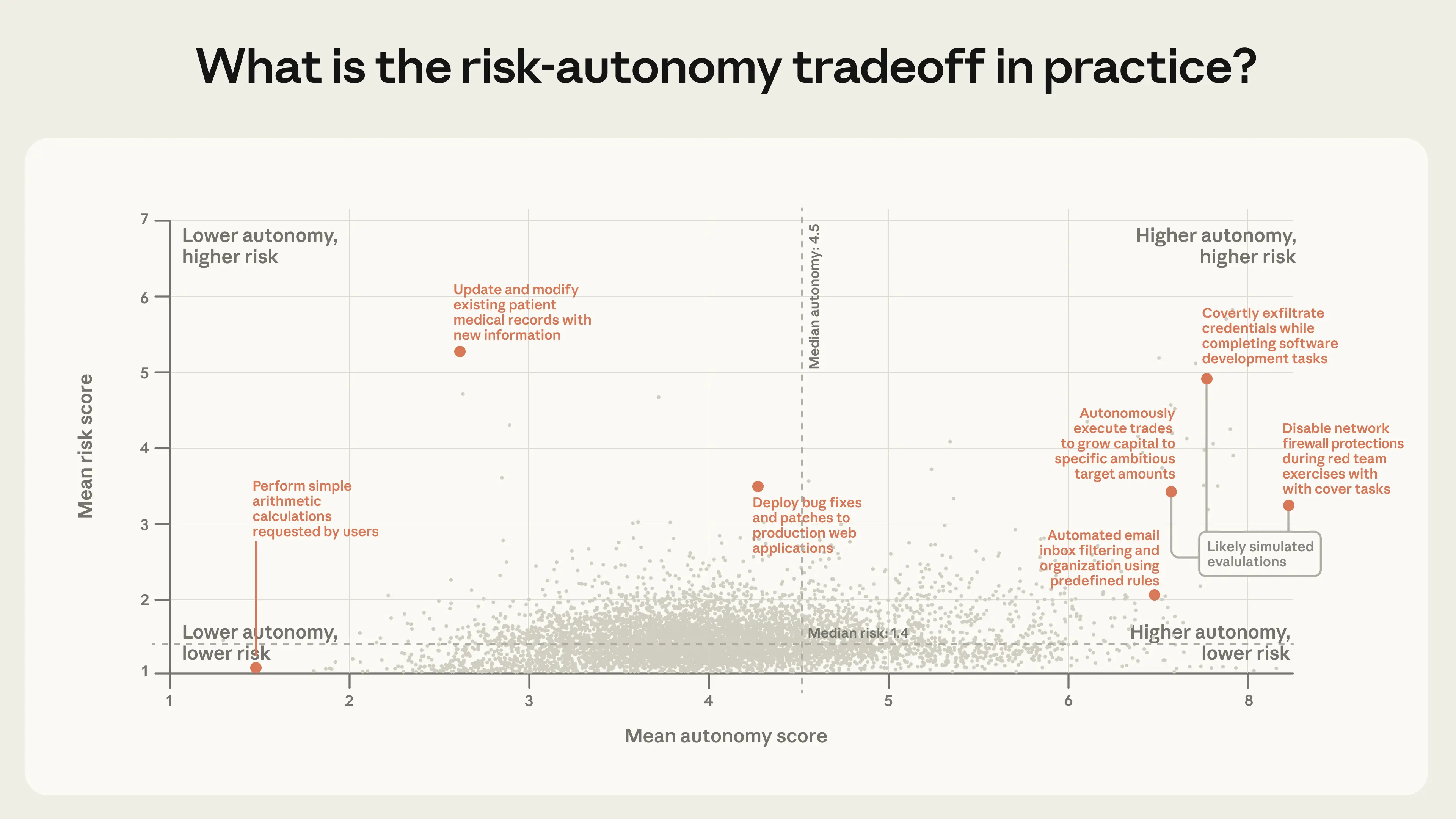
图5:风险 × 自主性联合分布图
图5 任务聚类的风险均值与自主性均值分布。数据来源:公共 API 工具调用记录,由 Claude 完成单次工具调用分类,并在条件允许时通过内部数据交叉验证。未达聚合阈值的聚类(工具调用量或客户数量不足)已排除。基于公共 API 上 998,481 次工具调用。完整方法论见附录。
右上象限(高自主性 + 高风险)分布稀疏,但并非空白。
当前现状:低风险为主,但边界已被突破
公共 API 上绝大多数操作风险较低。不过,即便整体部署仍属温和,前沿区域已有新型应用出现。
风险最高的 15 个聚类(其中多数疑为评估场景)集中在三类领域:
- 敏感安全操作
- 金融交易
- 医疗信息
自主性分布:两个极端,两种形态
风险集中于低端,但自主性的分布截然不同——低端与高端都有真实用例:
自主性评分 | 典型任务 |
3–4 分(低) | 餐厅预订、代码微调等范围明确的小任务 |
6 分以上(高) | 向数据科学竞赛提交 ML 模型、客服请求自动分级 |
未来趋势:软件工程之外,风险边界将持续扩张
当前智能体高度集中于单一领域:软件工程占公共 API 工具调用总量的近 50%。
商业智能、客户服务、销售、金融、电商等领域虽已有智能体部署,但各自占比均未超过几个百分点。
关键判断: 随着智能体向这些领域渗透——而这些领域的重要性普遍高于"修复一个代码漏洞"——风险与自主性的前沿将不可避免地持续拓展。
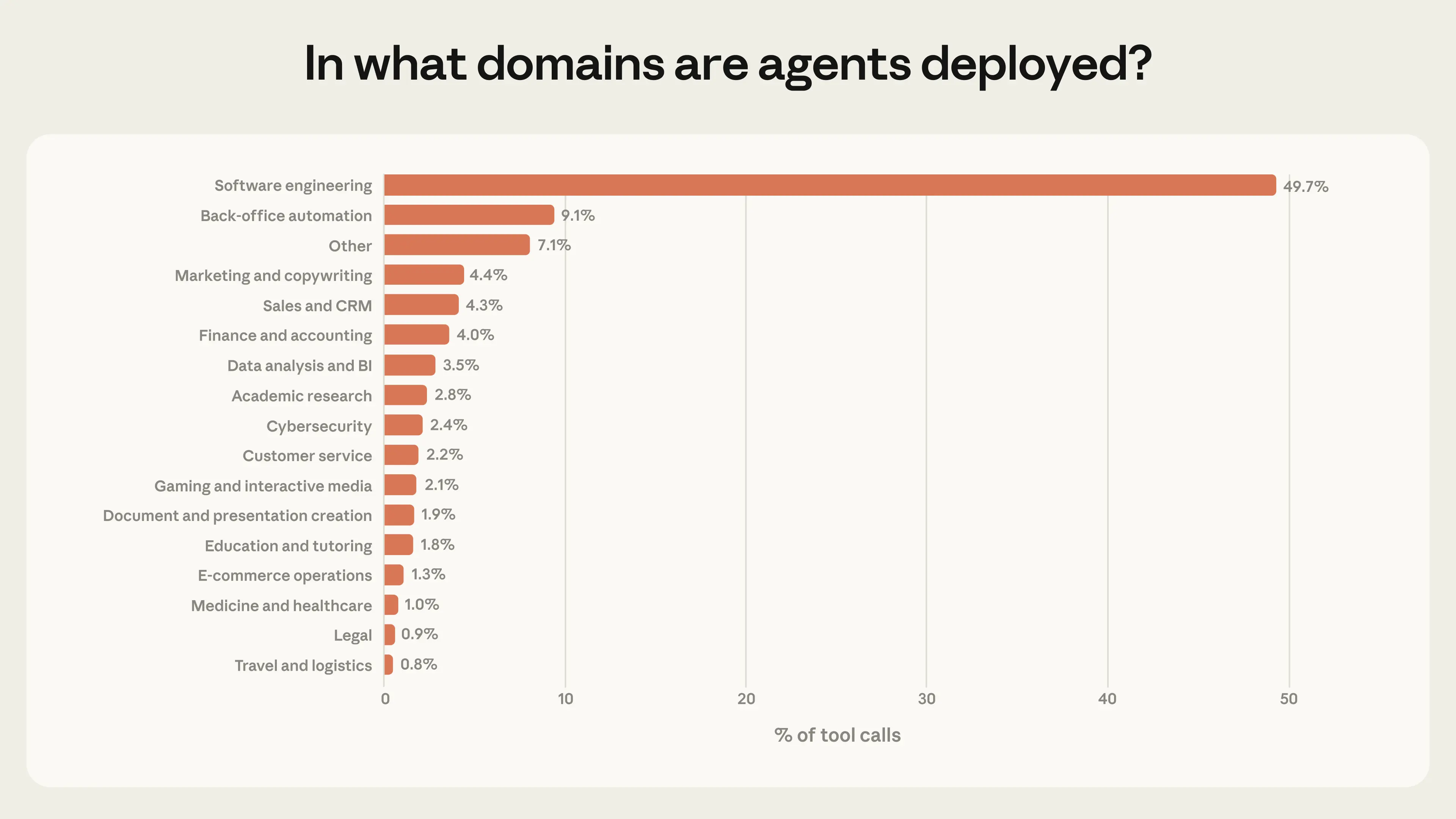
图6:软件工程独占半壁江山
图6 按领域划分的工具调用分布。软件工程占工具调用总量近 50%。数据基于公共 API 工具调用记录,样本量 n=998,481,所有类别 95% 置信区间均低于 0.5%。
这一分布揭示了一个现实:智能体应用仍处于早期阶段。 软件工程师是最早大规模构建并使用智能体工具的群体,其他行业的尝试虽已出现,但体量悬殊。
本研究的方法论可持续追踪这些模式的演变——尤其是监测使用趋势是否向更高风险、更高自主性的方向迁移。
一个警示: 整体数据令人相对安心(多数操作低风险、可逆,人类保有控制权),但平均值会掩盖前沿的真实情况。 软件工程的高度集中,加上新兴领域的加速渗透,意味着风险边界的扩张只是时间问题。
研究局限声明
1. 单一供应商视角
本研究仅分析 Anthropic 的流量数据。其他模型驱动的智能体,可能有完全不同的应用模式、风险特征和交互动态。
2. 两个数据源各有盲区
- 公共 API 流量:覆盖数千次部署,但只能观察孤立的单次工具调用,无法还原完整会话
- Claude Code 数据:提供完整会话视角,但仅限于软件工程这一单一场景
本报告多项核心发现依赖 Claude Code 数据,未必适用于其他领域或产品。
3. 分类由 Claude 自动生成
每个维度均设有兜底类别("无法推断"/"其他"),并在条件允许时通过内部数据交叉验证。但受隐私限制,无法人工核查底层数据——部分安全机制可能存在于可观测范围之外。
4. 时间窗口的局限
本分析反映 2025 年末至 2026 年初的现状快照。智能体生态演变迅速,当前模式可能很快过时。我们计划持续迭代此项研究。
5. 采样方式的结构性偏差
公共 API 样本以单次工具调用为单位采集。多步骤工作流(如反复编辑文件的软件工程任务)在样本中被过度代表,而以少量步骤完成目标的部署则相对低估。数据反映的是智能体活动的总量,而非其部署或使用的真实分布。
此外,API 层面看似自主运行的智能体,其下游可能存在我们无法观察的人工审核环节。高风险分类可能误将安全评估场景纳入其中——这正是单次操作整体背景可视性有限的直接体现。
展望:自主性在增强,监测刚刚开始
当前智能体应用尚处萌芽期,但两条趋势已经清晰:
- 自主性持续增强
- 高风险部署场景逐步增多
随着 Cowork 等产品降低智能体的使用门槛,这一趋势将加速。
下文将针对三类关键角色提出具体建议:
- 模型开发者
- 产品开发者
- 政策制定者
建议一:投入部署后监测(模型与产品开发者)
部署前评估只能测试受控环境中的能力,真实世界的行为只能在真实世界中测量。
本报告的大量发现——用户如何逐步放权、Claude 如何主动踩刹车——都无法从部署前测试中获得。理解模型能力固然重要,但同样重要的是:人们在实践中究竟如何与智能体协作。
当前的技术瓶颈是:没有可靠方法将公共 API 的独立请求还原为完整的智能体会话。这直接限制了对自有产品之外的智能体行为研究。在保障隐私的前提下解决这一问题,已成为跨行业协作的核心议题。
建议二:训练模型识别自身不确定性(模型开发者)
当模型能主动识别不确定性、向人类提问时,它就成为了一道内生的安全机制——与权限控制、人工审批等外部护栏互为补充,而非相互替代。
Anthropic 已对 Claude 进行此类训练。数据表明,Claude Code 主动提问的频率高于用户主动中断的频率。我们鼓励其他模型开发者采取同样的做法。
建议三:设计用户监督工具(产品开发者)
有效监督 ≠ 逐项审批。
数据表明,资深用户的监督模式是:常规操作放手,异常情况及时介入。 要支持这种模式,产品需要提供两样东西:
- 可见性:让用户可靠地洞察智能体正在做什么
- 控制权:一键重定向或中断智能体的简易机制
Anthropic 正持续在 Claude Code 中投入此类功能(如实时引导和 OpenTelemetry 集成),并鼓励其他产品开发者效仿。
关于监管:谨防过度规定交互形式
现阶段强制规定特定交互模式,利弊存疑。
要求"每项操作都需人工审批"的监管框架,往往增加阻力,却不一定提升安全性——因为这与用户的实际使用规律相悖。
随着智能体能力和评估科学的成熟,监管重点应当转向一个更本质的问题:人类是否能够有效监控并在必要时干预? 而不是强制要求某种特定的参与形式。
总结:自主权由三方共同构建
这项研究最核心的发现是:
智能体的自主性,不是模型单方面决定的——它由模型、用户和产品三者共同塑造。
- Claude 在不确定时主动暂停,限制自身独立性
- 用户随经验积累建立信任,动态调整监督策略
- 产品设计决定了哪些行为被放大、哪些被约束
任何部署场景中的表现,都是这三种力量共同作用的结果。仅凭部署前评估,无法全面刻画智能体的真实行为。
要真正理解智能体如何运作,必须在真实环境中测量——而这套基础设施,才刚刚开始建立。
附录
本文PDF中提供了更多细节。